目的別にわかるデータ分析手法の一覧 | Excel・Pythonで使える実践例も紹介

この記事をシェアする



この記事でわかること
- データ分析手法一覧
- データ分析のそれぞれの手法の進め方
- データ分析手法の選び方
- Excelでのデータ分析手法
- データ分析の失敗と解決策

執筆者 代表取締役社長 / CEO 杉山元紀
データ分析のお困りごとはプロにご相談ください
- 社内にデータが蓄積されていて分析を始めたいけど、まず何から学べばいいのか分からない
- 解決したい課題からデータ分析の目的を明確にし、それに合致した手法を採用したい
- データ活用の推進プロジェクトを立ち上げたもののプロジェクトが失敗してしまう
データに基づいた意思決定が求められる現代のビジネス環境において、「どの分析手法を使えばよいのか」と悩む方は少なくありません。特にデータ分析初心者にとっては専門的な言葉や手法の多さに戸惑い、最初の一歩を踏み出せないこともあるでしょう。
本記事では「データ分析 手法」に興味を持つすべての方に向けて、目的別に使い分けるべき主要な分析手法を網羅的に紹介します。分類・回帰・クラスタリング・因子分析など、ビジネス現場でよく用いられる手法の特徴と活用シーンを明確に解説。さらにExcelやPythonを活用した具体的な実践例も交えて、実務にすぐ活かせるノウハウをお届けします。
「分析を始めたいけど、まず何から学べばいいの?」という方にとって、本記事は最適なスタートガイドになるはずです。データ活用による課題解決と成果の最大化を目指して、ぜひ最後までご覧ください。
またデータ分析の基本について知りたい方は、こちらの記事もぜひご覧ください。
【初めてのデータ分析】ビジネスマン必須スキル!知っておきたいデータ分析の基本
目次
データ分析の基本とビジネスにおける重要性
データ分析は現代のビジネスにおいて「意思決定の質」を大きく左右する重要な活動です。経験や直感に頼る従来の経営手法から脱却しデータに基づく客観的な判断を行うことで、企業はより的確で迅速な意思決定が可能となり競争優位性を高めることができます。
ここではデータ分析の基本的な考え方から、企業における役割、そして分析結果をどう活用すべきかについて解説していきます。
データ分析とは何か|基本的な考え方と活用場面
データ分析とは集めた情報から価値ある「気づき」や「傾向」を導き出す一連のプロセスです。目的に応じて4つが主に活用されています。
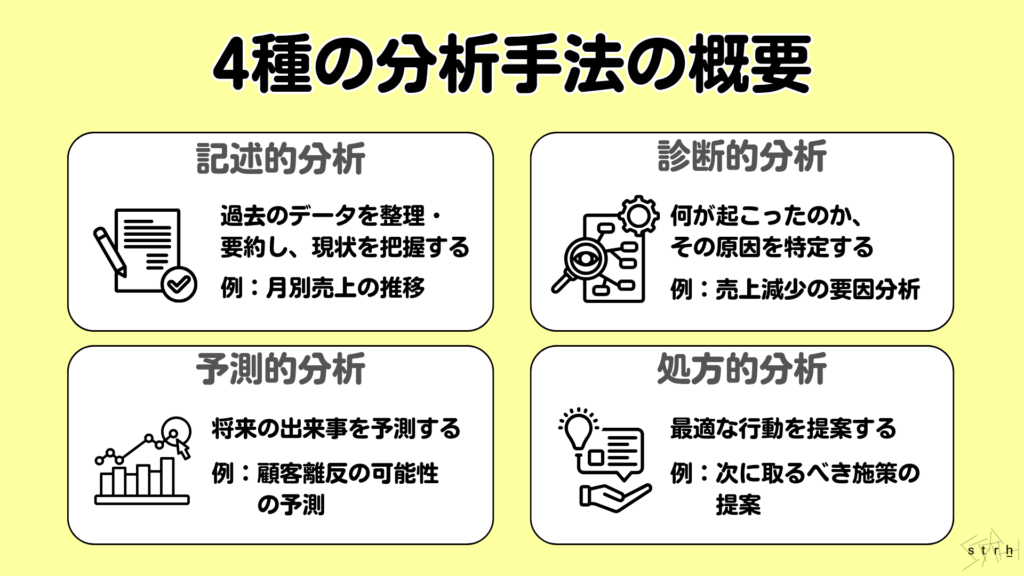
記述的分析は、過去のデータを集計して何が起こったのかを明らかにする手法です。この分析はデータの傾向やパターンを視覚化することに重点を置いています。例えば小売業者が月次売上データを分析し、特定の季節に売上が増加する傾向を把握することができます。そして12月に冬服の売上が急増することを特定し、今後の在庫計画に活かすことができます。
診断的分析は、記述的分析で得られた情報を基になぜそれが起こったのかを探る手法です。この分析は原因を特定することに焦点を当てています。例えば売上が前年よりも増加した理由を分析するためにマーケティングキャンペーンの効果を評価します。特定の商品が売上を伸ばした理由を調査し、成功要因を明らかにすることができます。
予測的分析では、過去のデータを基に将来の出来事を予測する手法です。この分析は、統計モデルや機械学習を用いて未来のトレンドや行動を予測します。例えば eコマースプラットフォームが顧客の過去の購入履歴を分析し、次に購入する可能性が高い商品を特定してターゲット広告を行うことができます。これにより顧客の購入意欲を高めることができます。
処方的分析は、予測的分析の結果を基に最適な行動を提案する手法です。この分析は、特定の状況においてどのようなアクションを取るべきかを示します。例えば企業が在庫管理を最適化するために過去の販売データを分析し、需要予測に基づいて最適な発注量を決定します。これにより在庫コストを削減し、顧客満足度を向上させることができます。
これらの分析は、それぞれが独立しているわけではなく、段階的に連携することで、データに基づいた実効性のある意思決定と行動へとつなげることができます。
これらの分析は業務のさまざまな場面で活用されています。例えばマーケティング部門では「どの顧客がリピートするか」の予測、営業部門では「どの施策が成果につながったか」の検証に役立ちます。
ビジネス課題にデータ分析が求められる理由
現在、環境変化のスピードが増し、過去の経験や勘だけでは的確な判断が難しくなっています。かつては個人の判断力やベテランの勘に頼っても成果が出る場面がありましたが、顧客のニーズや市場構造が多様化・複雑化した現在では、定量的な裏付けをもとに意思決定を行う必要性が高まっています。
また、業務のデジタル化が進んだことで日々の取引、顧客接点、業務プロセスなどあらゆる領域から膨大なデータが蓄積されるようになりました。これらのデータを活用できるかが企業の成長スピードや競争力を左右する重要な要素になっています。
例えばマーケティングでは広告効果の測定や顧客行動の可視化、営業では商談の成約確度やアプローチ優先度の分析、カスタマーサポートでは問い合わせ傾向の把握と対応品質の改善、人事では離職リスクの予測や適材適所の配置など、あらゆる場面でデータ活用が進んでいます。
つまり、データ分析は単なる技術ではなく組織が環境に適応し、持続的に成果を上げるための基盤であり、今や企業活動に不可欠な要素となっているのです。
分析結果を意思決定につなげるための視点
データ分析の目的は単に数値を算出したりグラフを作成したりすることではなく、その結果を的確な意思決定へと結びつけることにあります。しかし、分析結果が十分に活用されないまま終わってしまうケースは少なくありません。分析を実務に活かすためには、得られた結果を現場や経営層の意思決定に活用できるように解釈と戦略への落とし込みを丁寧に行うことが不可欠です。
まず前提として分析を開始する前の段階で「何を明らかにしたいのか」「どのような意思決定を支援するための分析なのか」といった目的を明確に設定することが重要です。目的が曖昧なままでは得られた結果に対する解釈が困難になり、実行可能な施策にもつながりません。
次に分析結果を読み解く際には「この結果は何を意味しているのか」「何をすべきか」といった視点を常に意識する必要があります。例えば「特定の顧客層の離脱率が高い」という事実が確認された場合、それ自体を報告するだけではなく「なぜ離脱が発生しているのか」「どのような施策によって改善が見込まれるか」までを導出することが求められます。
さらに実際の業務や施策へと反映させるには、分析結果を現場レベルで実行可能なアクションへと落とし込むプロセスが必要です。そのためには関係者との丁寧な合意形成と、わかりやすく筋道だった説明が重要です。数字を並べるのではなく、背景、意図、打ち手を含めたストーリー性のある説明が意思決定者の理解と納得を得る鍵となります。
このように、分析結果を実際の意思決定へとつなげるためには「目的の明確化」「結果の解釈」「行動への具体化」という三つの視点を持ち続けることが重要です。分析手法やツールに精通することも大切ですが、それ以上に分析結果をいかに実務に落とし込むかという運用視点がデータ分析の価値を最大限に引き出すための本質的な要素となるのです。
マーケティング効果測定を正しくできていますか?指標や手法、ツールをわかりやすく解説
代表的なデータ分析手法一覧とその分類
データ分析には様々な手法が存在しますが、分析の目的やデータの種類によって使い分ける必要があります。ここからは、代表的な手法を「分類・予測」「相関・要因分析」「グルーピング・傾向発見」の3カテゴリに分け、それぞれの特長や使いどころを詳しく解説します。
分類・予測に役立つ分析手法とは
「分類」と「予測」は、未来の行動や状態を事前に知るために欠かせない分析手法です。顧客が商品を購入するかどうか、売上が来月どうなるかといった意思決定のヒントを与えてくれます。
ここでは以下に代表的な手法を紹介します。
決定木分析|意思決定を図で表現
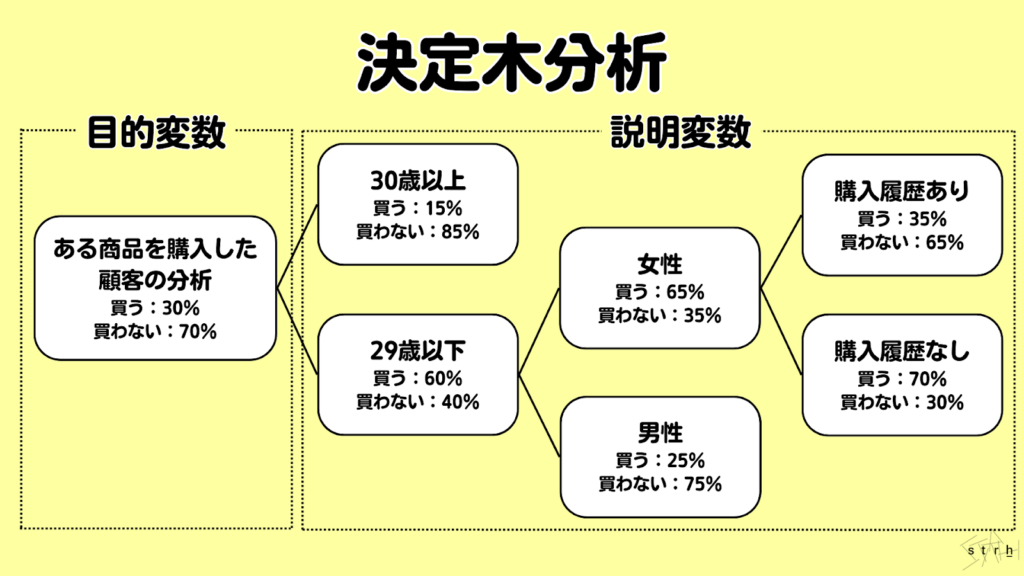
決定木分析とは複数の条件を分岐させながら分類や予測を行う手法であり、判断のプロセスをツリー構造で視覚的に表現できる点が大きな特長です。分析結果が図として明示されるため専門知識のないユーザーでも直感的に理解しやすく、現場での説明や意思決定にも活用しやすい点で高く評価されています。
この手法は、ある目的変数(例:購買の有無)に対して、影響を及ぼす複数の説明変数(例:年齢、性別、購入回数など)を段階的に分岐させることで「どの条件が最も重要か」「どのようなルートで分類されるか」を明らかにします。最終的な出力は「葉(リーフ)」と呼ばれる分類結果となり、それまでの分岐条件がロジックとして可視化されます。
例えば、「20代・女性・購入履歴なし」といった条件が揃うと購買確率が高いと判断されるようなツリー構造が形成されます。このようにして、特定の条件下での行動パターンや傾向を整理し、マーケティング施策やターゲティング戦略の立案に活かすことが可能です。
さらに決定木分析は、解釈性が高い一方で機械学習モデルの一部としてより複雑なアルゴリズム(ランダムフォレストや勾配ブースティングなど)にも応用されており、シンプルながら実用性の高い分析手法として幅広い業務領域で用いられています。
顧客インサイトとは?分析方法や見つける際のポイント、成功事例を解説!
ロジスティック回帰|確率で分類する分析法
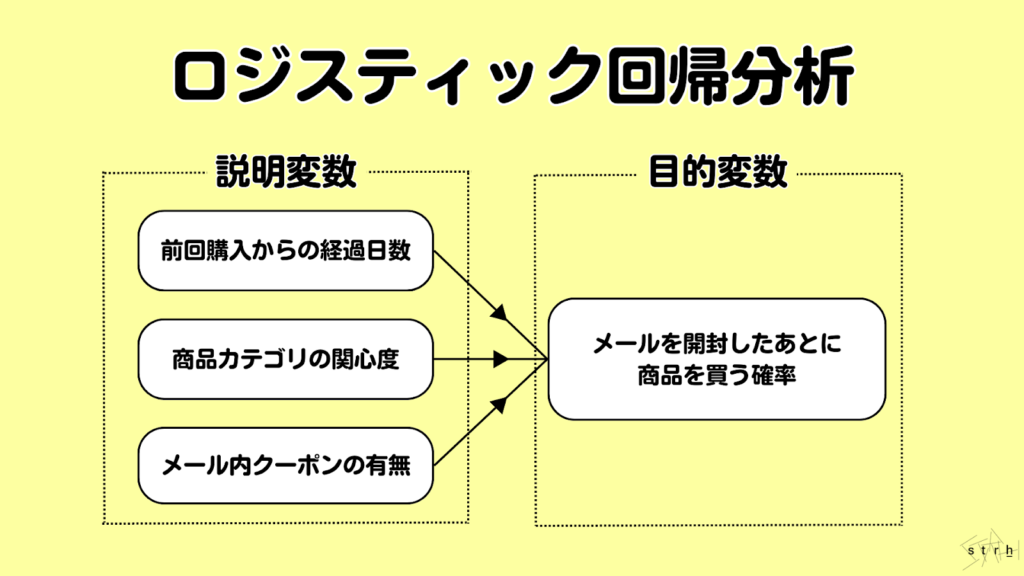
ロジスティック回帰分析は、目的変数が「はい/いいえ」「購入する/しない」など二値の分類問題に適した統計モデルであり、ある事象が発生する確率を予測することができます。従来の線形回帰分析が数値予測を目的とするのに対し、ロジスティック回帰は0から1の範囲で確率を出力し、一定の閾値を超えるか否かによって分類を行う点に特長があります。
この手法では説明変数(年齢、性別、購買履歴など)と目的変数との間に対数オッズ比(logit)という関係を仮定し、事象が起こる可能性を論理的に数式化することができます。例えば「特定のメールキャンペーンに反応して商品を購入する確率」を予測する場合、ロジスティック回帰を用いれば、どのような属性の顧客が反応しやすいかを定量的に把握することが可能です。
さらにロジスティック回帰分析では、各説明変数が目的変数に与える影響の大きさを係数として得ることができるため、変数ごとの重要度や方向性(正の影響か負の影響か)を明確に評価できます。これは単に分類を行うだけでなく、分析結果を基に戦略的な施策を検討する上でも有効です。
その解釈性の高さと応用範囲の広さからロジスティック回帰はマーケティング、与信審査、医療、人材分析など幅広い業種・目的で活用されている汎用性の高い手法となっています。
スコアリングとは?BtoBマーケティングにおけるリードスコアリングのポイントについて解説
ランダムフォレスト|複数の決定木で高精度分類
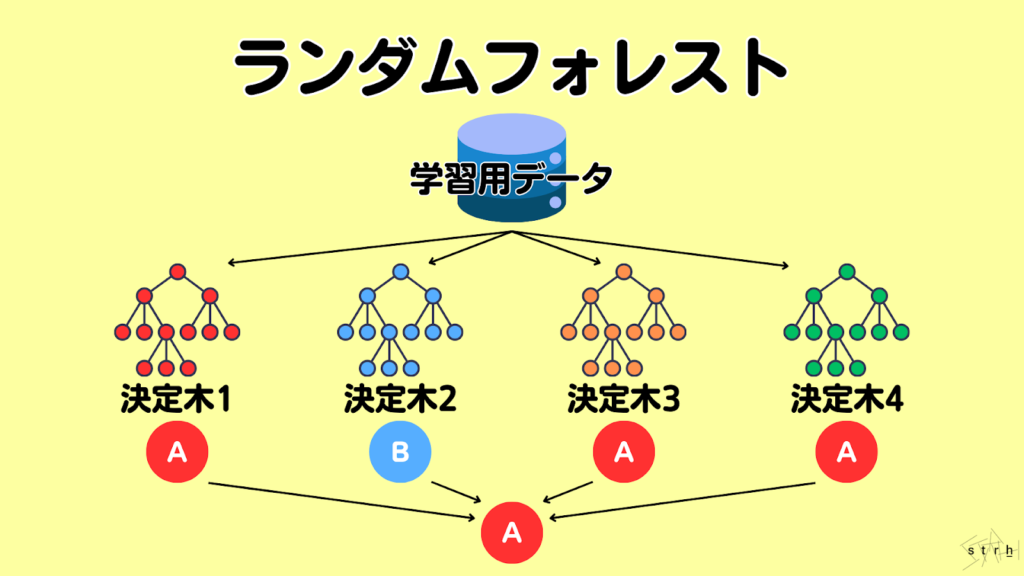
ランダムフォレストは、複数の決定木を組み合わせて予測を行うアンサンブル学習の一手法であり、分類・回帰の両方に対応可能な高性能なモデルです。単一の決定木は構造が単純な分、過学習を起こしやすいという課題がありますがランダムフォレストでは多数の決定木を生成し、それぞれの予測結果を集約することで安定した高精度な予測を実現します。
この手法の特長は、各決定木の作成において「ブートストラップ法」と「特徴量のランダム選択」が行われる点にあります。これにより各木が異なる視点で学習を行うため、モデル全体としての汎化性能が向上し、未知データに対しても強い耐性を持つことができます。
実務においては、例えば顧客の購買予測、クレジットカードの不正利用検知、医療データにおける疾患の分類など多変量かつ複雑な構造を持つデータに対する精度の高い分析が求められる場面で広く活用されています。
また変数ごとの重要度を出力できるため、ブラックボックス化しがちな機械学習モデルの中でも説明性と透明性をある程度担保できるという点もビジネスでの活用において大きな利点となっています。
相関・要因を探る分析手法とは
ビジネスの課題を深掘りするうえで「何が影響を与えているのか?」という因果関係や相関関係の特定は非常に重要です。売上に影響している要素は広告費なのか、顧客属性なのかという問いに答えるには、数値同士の関係性を定量的に分析する必要があります。
ここでは、数値の関係性や背後にある要因を探るために使われる代表的な手法を紹介します。
回帰分析|数値の関係性を明らかにする
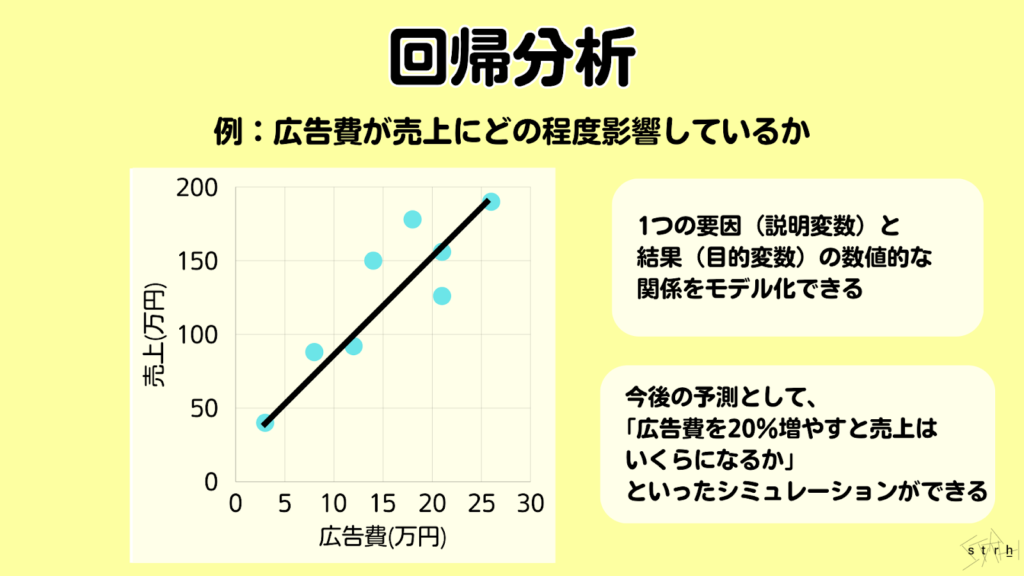
回帰分析とは、ある変数(目的変数)を他の変数(説明変数)によってどの程度説明できるかを明らかにするための統計的手法です。複数のデータの背後にある数値的な関係性をモデル化し、変数間の相関構造や影響度を可視化・定量化することができます。
代表的なものが単回帰分析で、1つの説明変数が目的変数に与える影響を直線で表現します。例えば「広告費が増えると売上がどのように変動するか」といった因果関係を把握する際に用いられます。一方で複数の要因が絡む現実のビジネス課題では、複数の説明変数を同時に扱う重回帰分析が適しています。
回帰分析の主な目的は、過去のデータをもとに将来の数値を予測したり、影響力の高い要因を特定したりすることです。係数の正負を見れば、ある要因が目的変数にどのような方向で影響を及ぼしているのかが分かり、意思決定の根拠としても活用できます。
ビジネスにおいては売上・顧客数・離分かり職率・満足度といった様々なKPIの分析に用いられ、戦略立案や施策評価を数値的な裏付けのもとで行うための基本的かつ汎用性の高い手法です。
因子分析|背後にある要因を特定
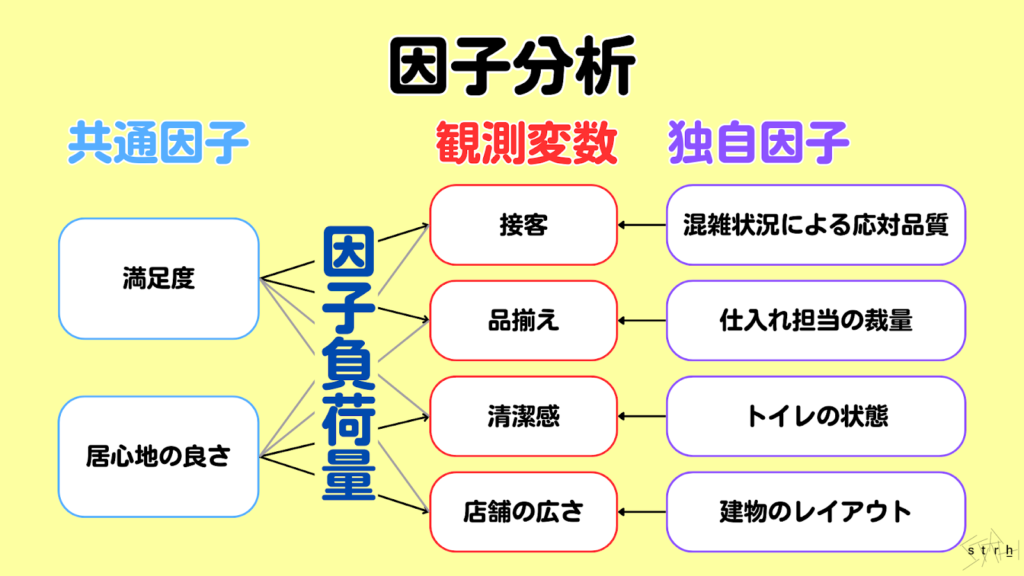
因子分析は、複数の観測項目の背後にある共通の潜在的な構造(=因子)を明らかにするための多変量解析手法です。表面的には異なるように見える多数のデータが実は共通の要因によって説明できるという前提に基づき、変数間の相関をもとに構造を単純化し要因の本質を抽出します。
例えば顧客満足度調査において「接客」「店内の清潔さ」「品揃え」「待ち時間」など複数の評価項目があった場合、それらの回答傾向に共通する背後の因子として「サービス品質」や「店舗利便性」などが浮かび上がることがあります。こうした因子を特定することで改善すべき本質的な課題や訴求ポイントを明確にすることが可能になります。
実務ではマーケティングリサーチや人事領域のエンゲージメント調査、教育分野の理解度分析などで活用されており、数値に表れにくい心理的要素や構造的な問題の特定に非常に有効です。また特定された因子はクラスタリングや回帰分析と組み合わせることでより実践的な戦略設計にもつなげることができます。
重回帰分析|複数の要因を同時に分析
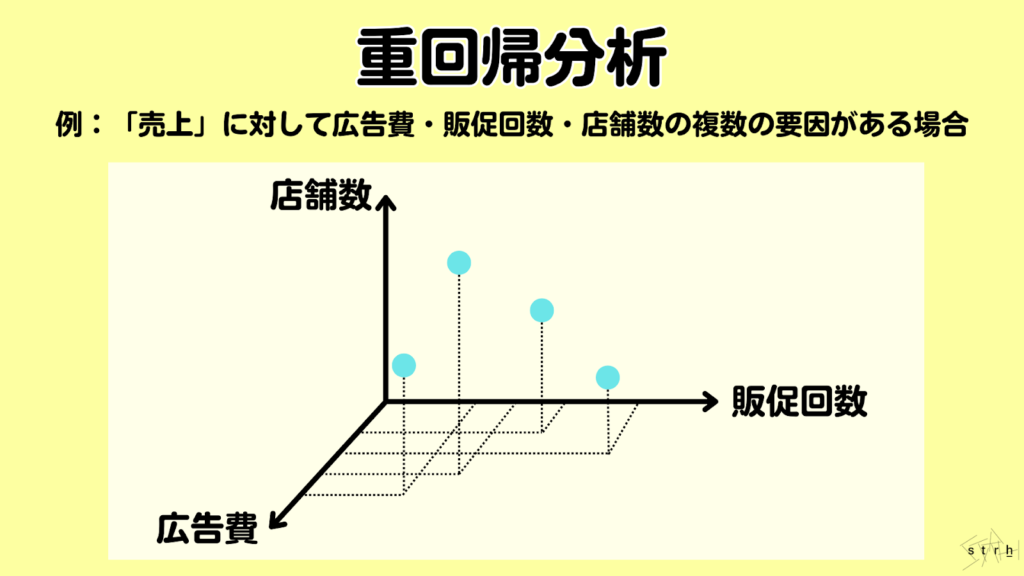
重回帰分析は、複数の説明変数が目的変数に対してどのように影響しているかを同時に解析する統計手法です。単回帰分析が1対1の関係を扱うのに対し、重回帰分析では複数の要因を同時に加味できるため、現実のビジネス課題により近い形で因果関係を把握することが可能です。
例えば「売上」に影響を与える要素として「広告費」「店舗数」「販売員数」など複数の変数が考えられる場合、それぞれの要因が売上にどの程度寄与しているのかを定量的に測定できます。各変数の回帰係数を確認することでどの施策が最も効果的か、逆にどの要因は影響が小さいのかといった示唆が得られます。
また重回帰分析では、各変数が他の変数とどの程度相関しているか(多重共線性)をチェックすることも重要です。VIF(分散拡大係数)などを用いてモデルの信頼性を確保しながら分析を進める必要があります。
実務では売上予測、人員配置、価格最適化など幅広い分野で活用されており、複雑な意思決定において複数の要因を同時に考慮した戦略立案を可能にする基盤的な分析手法です。
主成分分析(PCA)|多変量データの次元圧縮と傾向把握
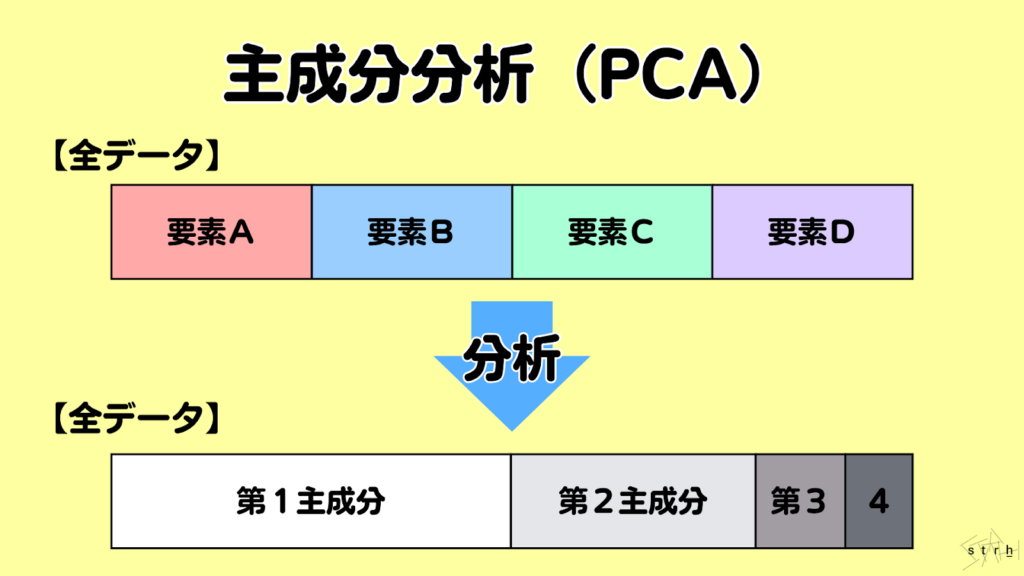
主成分分析(PCA:Principal Component Analysis)は、複数の変数を持つデータセットに対して変数間の情報をできる限り損なわずに少数の「主成分」と呼ばれる新たな軸に変換し、次元を圧縮する手法です。これによりデータの構造や傾向を視覚的・定量的に把握しやすくなります。
例えば顧客の年齢、収入、購買頻度、訪問回数など複数の変数を持つデータに対して主成分分析を実施するとそれらの変数の分散を集約した「軸(主成分)」が導き出され、データのばらつきや特徴的なパターンを2次元や3次元で可視化することが可能になります。
この分析により、変数間の相関が高い場合でも重複する情報を削減し、本質的な特徴のみに集約したシンプルなデータ構造が得られるため、分析の前処理や視覚的なクラスタ傾向の把握にも非常に有効です。
実務ではマーケティングの顧客セグメントの分析やアンケート結果の整理、画像・音声処理の前処理など情報の圧縮やノイズ除去が求められるシーンで広く活用されています。主成分分析は、高次元データの理解を助けると同時にその後の機械学習や可視化の精度と効率を高める基盤的な手法です。
顧客セグメントとは?作り方や活用の流れ、成功事例を分かりやすく解説
グルーピング・傾向発見に有効な分析手法
多様化する顧客や商品に対してひと括りにするのではなく、似た傾向を持つグループに分けて対応することは、マーケティングや業務改善において極めて重要です。グルーピングによって施策をより効果的に展開したり、個別最適なアプローチを設計することが可能になります。
ここでは、データの背後にある「似た者同士」や「隠れたルール」を発見するための代表的な手法を紹介します。
クラスター分析|似た特性でグルーピング
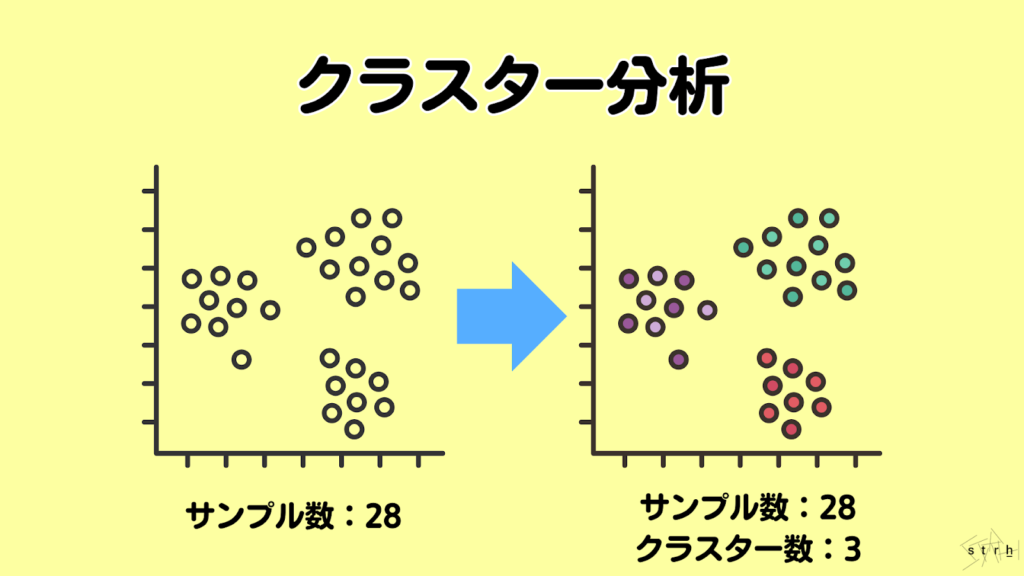
クラスター分析とは、観測データの中から類似した特徴を持つ対象を自動的にグループ化(クラスタリング)する多変量解析手法です。分類ラベルを持たないデータに対して、「似ているもの同士は同じグループに属する」という前提に基づいて構造的なまとまりを明らかにすることができます。
例えば顧客の年齢、購買頻度、商品カテゴリなどのデータからクラスター分析を実施することで「価格重視型」「リピート購入型」「ブランド志向型」などの購買傾向に基づくセグメントを自動で抽出することが可能です。これにより画一的な施策ではなく、グループごとの特性に応じたマーケティング戦略や商品開発が実現します。
主な手法としては、k-means法や階層型クラスタリング、密度ベースクラスタリング(DBSCAN)などがあり、データの性質や目的に応じて使い分けることが求められます。また主成分分析と組み合わせることで高次元データの可視化や傾向把握が一層容易になります。
クラスター分析は、マーケティング、商品戦略、顧客管理など幅広い業務に応用されており、違いを捉えることにより意思決定の精度を高める有効な手段として高く評価されています。
現場でも混同しがちなセグメンテーションとターゲティングの違いとは?
アソシエーション分析|購買傾向を抽出
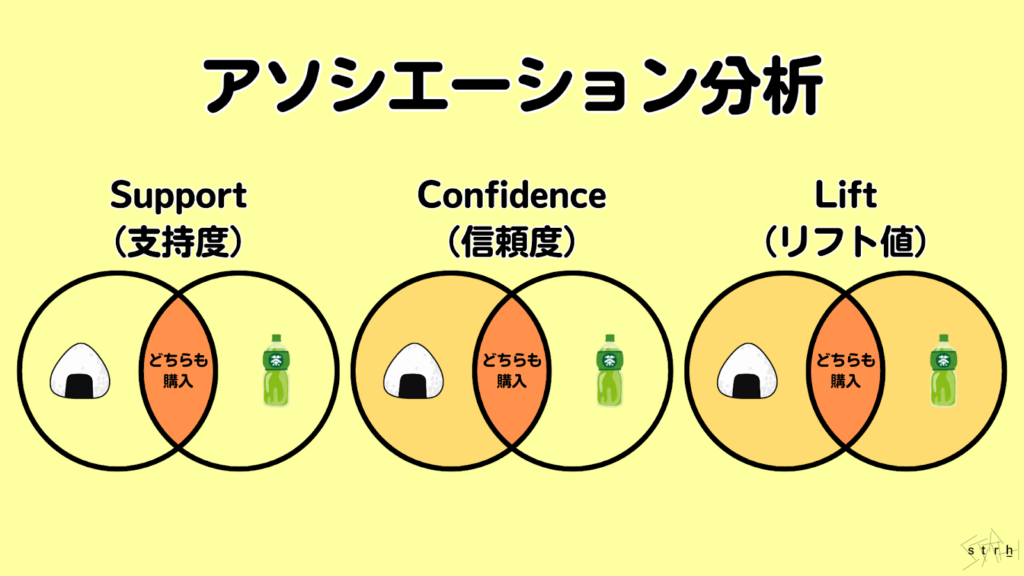
アソシエーション分析(関連ルール分析)は、顧客の購買履歴や行動データから「Aを購入した人はBも購入する傾向がある」といった項目間の関連性(アソシエーション)を抽出する分析手法です。スーパーマーケットのレジ通過データなどを活用した「バスケット分析」としても知られています。
この分析は商品の組み合わせにおける共通パターンを明らかにし、クロスセル施策やレコメンドエンジン、陳列戦略の設計などに広く活用されています。例えば「おにぎりとお茶」「パスタとソース」といった購買関係が高頻度で確認された場合、それらを同時にプロモーションすることで販売機会の最大化が図れます。分析結果は主に以下の3つの指標で評価されます。
- Support(支持度):全体の中でそのルールがどれくらい出現するか
- Confidence(信頼度):Aが買われたときにBが買われる確率
- Lift(リフト値):AとBが一緒に買われる確率が偶然以上かどうかの指標
これらを組み合わせて分析することで、単なる頻度ではなく施策として有効性の高い商品関連性を特定できます。アソシエーション分析は、顧客理解を深め、販売戦略に科学的根拠を与える手法としてマーケティング実務において極めて有用です。
Excelで試せる基本的なデータ分析・集計手法
データ分析と聞くとPythonやSQLなどのプログラミングスキルが必要と思われがちですが実はExcelでも実務レベルの分析は十分に可能です。特に初心者や非エンジニアにとっては操作に慣れたExcelを使うことで分析へのハードルを下げることができます。
ここでは、業務でよく使われる代表的なExcel分析手法を3つ紹介し、それぞれの活用場面とポイントを解説します。
クロス集計|属性別の傾向を可視化
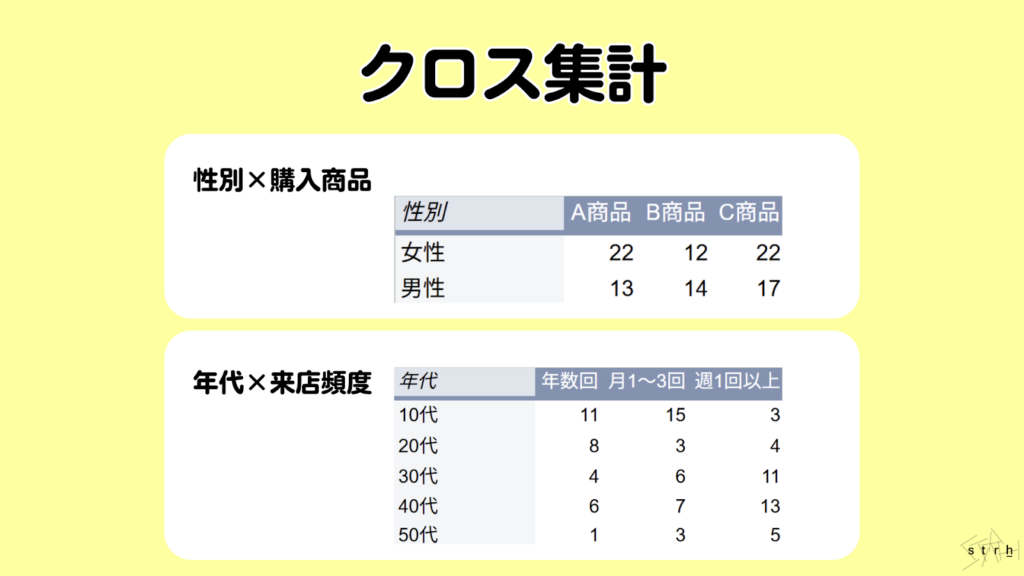
クロス集計は、複数のカテゴリ変数を掛け合わせて集計を行うことで属性別の傾向や関係性を把握するための基本的かつ実用的な分析手法です。マーケティングにおいては、顧客の性別・年代・地域・購買履歴などといった属性と、購買行動や商品評価などの結果変数を組み合わせて集計することで、どの属性がどのような傾向を持つかを直感的に把握することができます。
例えば「年代別×商品認知率」「性別×キャンペーン反応率」などをクロス集計することでターゲット層ごとの興味関心や反応特性を具体的に可視化でき、施策設計やセグメント別アプローチの精度を高めることが可能です。
また集計結果をグラフやヒートマップとして視覚化することで、社内共有や施策の説明資料としても活用しやすく、意思決定のスピード向上にも寄与します。定量的な全体傾向を把握しながら部分的な違いや傾向を明らかにする手段として、クロス集計はマーケティング分析における初動段階で特に重要な役割を担います。
ピボットテーブル|自由なデータ集計
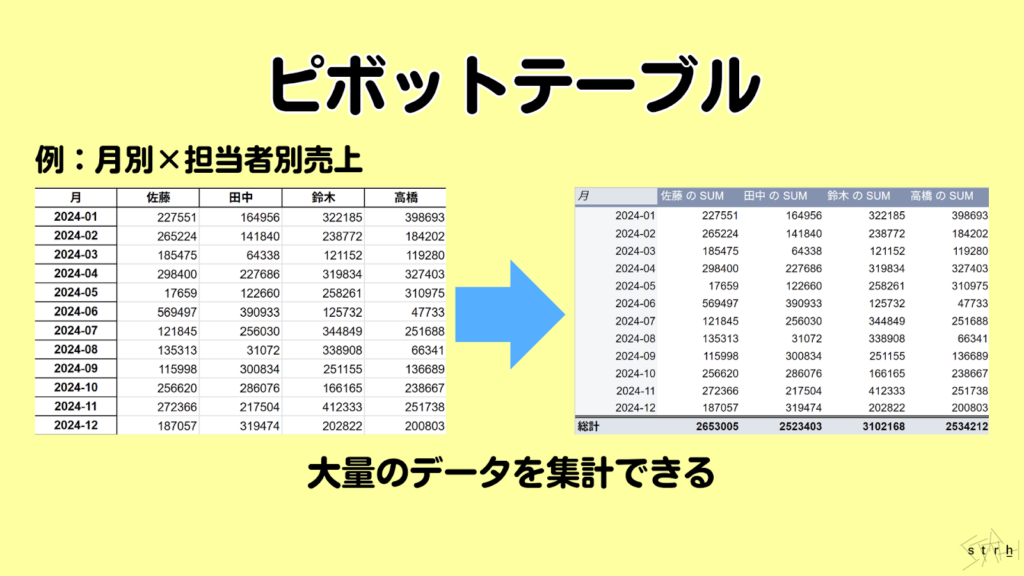
ピボットテーブルは、Excelにおける代表的なデータ集計機能であり、大量のデータを任意の切り口で柔軟に集計・分析することが可能なツールです。行や列、値の項目をドラッグ&ドロップするだけで目的に応じた集計表を瞬時に作成できるため、日常業務における分析業務の効率化に大きく貢献します。
マーケティング業務においては、顧客属性ごとの売上分析やキャンペーン別の反応集計、商品カテゴリ別の購買傾向の把握などさまざまな視点からデータを動的に集計し、ニーズに応える強力なツールとして活用されています。また、フィルタやスライサー機能を活用すれば特定条件での絞り込みや比較も簡単に行うことができ、多角的な視点からの意思決定をサポートします。
分析の専門知識がなくても直感的に操作できる点に加え、リアルタイムで集計結果を確認・調整できる柔軟性は、スピーディかつ的確な施策検討やレポート作成を求められるマーケティング現場において極めて有用です。ピボットテーブルは、データ分析の入口としても日常的なレポート作成の効率化手段としても高い実務価値を備えたツールといえます。
散布図・相関分析|視覚的な関係性の把握
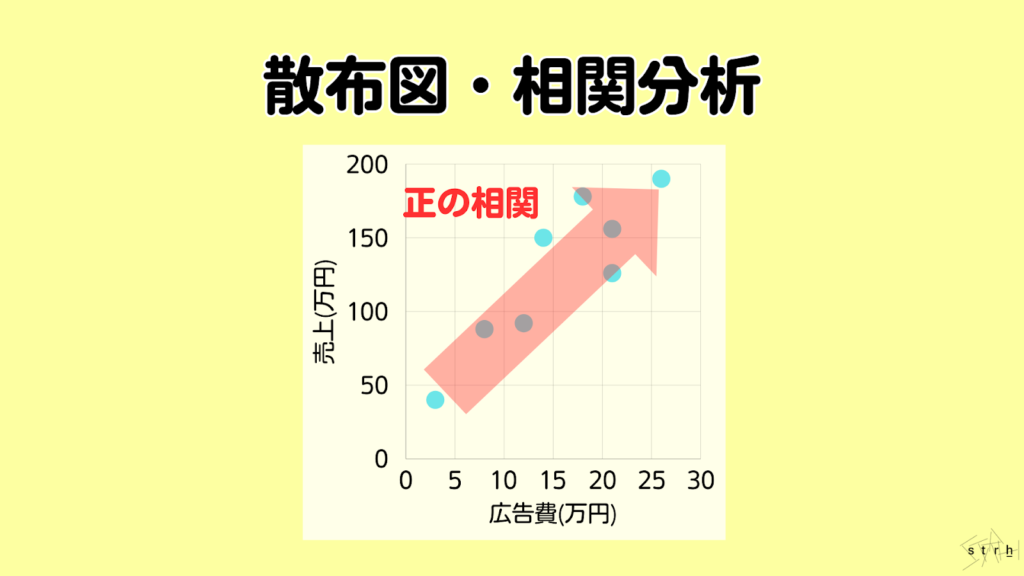
マーケティング施策において異なる要素間の関係性を把握することは、施策の因果関係を考察するうえで重要な出発点となります。散布図は、2つの変数の関係を視覚的に確認できる代表的な分析手法であり、各データポイントをXY軸上にプロットすることで相関の有無や傾向、外れ値の存在などを直感的に捉えることができます。
例えば「広告費と売上」「メール配信回数と開封率」などマーケティング活動で用いる数値間の関係を散布図に落とし込むことで、正の相関・負の相関・相関なしといった関係性を把握できます。これにより、どの指標が成果に影響を与えているのかを明確にし、次回施策の調整や優先順位付けの根拠とすることが可能です。
さらにExcelなどのツールを用いれば相関係数の算出も容易であり、視覚的判断に加えて定量的な裏付けに基づく意思決定が実現します。施策評価だけでなく仮説検証やリスク分析の初期段階にも活用できる汎用性と即時性に優れた分析手法です。
目的別で見るデータ分析手法の選び方
データ分析の手法は多岐にわたりますが、「どの手法を使うべきか」は分析の目的によって異なります。すべての分析を網羅的に行うのではなく、限られたリソースの中で成果を出すためには「目的」から逆算して手法を選ぶ視点が重要です。
本章では「マーケティング」「業務効率化」「顧客満足度向上」という3つの主要な領域において最適な分析手法とその使い方を具体例とともに紹介します。
マーケティングで活用すべき手法とその理由
マーケティング分野では、「誰に・何を・どのように届けるべきか」を明らかにすることが求められます。顧客理解を深め施策の精度を高めるために、以下のような手法が有効です。
購買傾向を活かしたクロスセル戦略|アソシエーション分析の活用法
アソシエーション分析は、顧客の購買履歴から関連性の高い商品組み合わせを抽出することでクロスセル施策に有効なインサイトを提供します。例えば「Aを購入した顧客はBも購入する傾向がある」といったルールを導き出すことで商品提案の精度を高め、顧客単価の向上を実現します。
マーケティングにおいてはセット販売やレコメンド機能、販促キャンペーンの最適化などに活用され、顧客満足度を損なうことなく売上増加を図る戦略的アプローチとして非常に有効です。
顧客の行動パターンで施策を分ける|クラスター分析によるセグメント化
クラスター分析は、購買履歴や行動データに基づいて顧客を類似グループに分類し、それぞれに最適な施策を設計するための基盤となる手法です。マーケティング活動では、画一的な施策ではなく「誰に、何を、どのように届けるか」をセグメントごとに最適化することが成果の鍵を握ります。
クラスター分析を活用すれば、価格重視型・リピート型・休眠予備軍などの傾向別にアプローチでき、顧客ごとのロイヤルティ向上やLTV最大化に貢献します。
キャンペーン施策を予測する|ロジスティック回帰の応用
ロジスティック回帰は、過去の反応データをもとに「どの顧客がキャンペーンに反応する可能性が高いか」を確率で予測する手法です。限られた広告予算の中で高い成果を上げるためには、確度の高いターゲットを事前に見極め、的確にアプローチすることが求められます。
この手法を活用することで無駄な配信を避け、効率的かつ効果的な施策運用が可能になります。また、各要因の影響度が数値で把握できるため、施策改善の論拠としても活用できます。
広告投資の最適配分を導く|回帰分析で見る予算と成果の関係
回帰分析は、複数の広告チャネルが売上に与える影響を定量的に評価し、どの施策にどれだけの予算を配分すべきかという判断を支援する分析手法です。特に複数のマーケティング施策を同時並行で展開している企業にとって、施策ごとの投資対効果を比較し、最適な資源配分を行うことは極めて重要です。
回帰分析を活用すれば単なる効果測定にとどまらず、今後のシミュレーションやROI最大化に向けたデータドリブンな戦略設計が可能となります。
顧客の行動要因を見える化する|マーケティングにおける決定木分析の効力
マーケティングにおける意思決定では、「なぜ顧客がその行動を取ったのか」を明らかにすることが施策改善の起点となります。決定木分析は、顧客の属性や行動履歴をもとに特定の行動に影響を与える要因とその組み合わせをツリー構造で可視化できるため、施策設計における説明性と説得力が高まります。
さらに社内の非専門部署にもわかりやすく伝えられるため、合意形成や実行フェーズへの移行がスムーズになる点でも非常に実用的な分析手法です。
業務効率化に向く分析アプローチ
業務のムダや非効率の改善は組織全体の生産性向上に直結します。データを活用すれば作業のばらつきや時間の浪費、重複工程などを定量的に可視化し、改善ポイントを明確にすることが可能です。
ここでは、現場業務の効率化を目的とした代表的な分析手法と実務における活用シーンを紹介します。
業務の全体像を比較して効率化の糸口を探る|クロス集計の活用例
クロス集計は、異なる観点からデータを比較することで業務の全体像を把握し、効率化のポイントを見つける手法です。例えば部門別や担当者別、月別のデータを組み合わせることで特定の業務プロセスにおけるパフォーマンスの違いや傾向を明らかにできます。
この手法を用いることでどの部門が効率的に業務を遂行しているか、またはどの時期に業務が滞っているかを視覚的に理解しやすくなります。これにより改善が必要な領域を特定し、具体的な対策を講じることが可能になります。
重複作業を洗い出して改善へ導く|PCAによる業務傾向の分析
主成分分析(PCA)は、多次元データを少数の主成分に集約することで、データの傾向を明確にする手法です。この分析を通じて、業務における重複作業や非効率なプロセスを特定できます。
例えば複数の業務プロセスに関連するデータをPCAで分析することでどの要因が業務の効率を低下させているかを明らかにし、改善策を導き出すことができます。PCAを活用することで業務の本質的な問題を把握し、効果的な改善策を実施するための基盤を築くことができます。
非効率な業務の根本原因を明らかにする|因子分析の使い方
因子分析は、複数の変数間の関係性を明らかにし、業務の非効率の根本原因を特定するための手法です。この分析を通じて、業務プロセスに影響を与える主要な因子を抽出し、それらがどのように業務の効率に寄与しているかを評価できます。
例えば顧客満足度調査のデータを因子分析することで、顧客の不満の原因を特定し、改善策を講じることが可能になります。因子分析を用いることで、業務の改善に向けた具体的なアクションプランを策定するための洞察を得ることができます。
時間とコストの関係を可視化して改善余地を見つける|散布図分析
散布図分析は、二つの変数間の関係性を視覚的に表現する手法です。このアプローチを用いることで業務における時間とコストの関係を明らかにし、改善の余地を見つけることができます。
例えばプロジェクトの進行時間とそのコストを散布図で表示することで時間の無駄遣いやコストオーバーの原因を特定し、効率的な業務運営に向けた対策を講じることができます。
自動化可能なルールを構築する|業務最適化における決定木分析の応用
決定木分析は、業務データを基に条件分岐のルールを視覚的に表現する手法です。この手法を用いることで、業務プロセスの自動化が可能なルールを構築できます。
例えば顧客の行動データを分析し、特定の条件に基づいて自動的にアクションを起こすルールを設定することで業務の効率化を図ることができます。決定木分析を活用することで業務の最適化を進め、リソースの無駄を省くことが可能になります。
顧客満足度向上のための分析法とは
顧客が商品やサービスにどのような印象を持ち、再利用・リピートにつながるかを見極めるには、定性的・定量的なデータの両方を活用した分析が不可欠です。単なる「満足・不満足」の判断ではなく「なぜそのような評価になったのか」を明らかにすることで、改善策の精度とスピードが飛躍的に高まります。
ここでは、顧客満足度を向上させるために効果的な4つの分析手法を具体的に解説します。
顧客の声から不満要因を読み解く|テキストマイニングの活用法
顧客満足度を高めるためには定量的な指標だけでなく自由記述などに含まれる顧客の生の声を的確に読み解くことが重要です。テキストマイニングは、アンケートやレビュー、問い合わせ対応履歴などの非構造データを解析し、頻出ワードやキーワードの共起関係を可視化する手法です。
この手法を活用することで表面的な評価点数では見えてこない不満の本質や潜在的ニーズを抽出でき、プロダクト改善や訴求軸の見直しに直結する貴重な示唆が得られます。また、ポジティブ/ネガティブの感情分析を組み合わせることで評価の背景にある心理や感情的傾向の把握も可能になり、ブランド価値の向上に向けたコミュニケーション施策の質を高める一助となります。
顧客層を分け、改善に活かす分析手法|NPSスコアの活用
NPS(Net Promoter Score)は、顧客が企業やブランドを他者に推奨したいと思うかどうかを数値で把握できる指標であり、ロイヤルティを軸とした顧客分類と施策立案に非常に有効です。マーケティングの実務においては、顧客を「推奨者」「中立者」「批判者」の3層に分け、各セグメントに応じた対応策を講じることで離反の防止とファン育成の両面にアプローチできます。
例えば批判者に対してはクレーム要因の解消やアフターフォロー強化を、中立者にはエンゲージメントを高めるコミュニケーション設計を、推奨者には口コミ促進やアンバサダープログラムの導入を行うことで、スコアの向上とLTV最大化を同時に目指す戦略的な運用が可能となります。
顧客満足度に効く施策を見極める|重回帰分析による優先度の特定
顧客満足度を向上させるためには、各施策や要因がどの程度顧客満足度に寄与しているのかを明確に把握することが不可欠です。重回帰分析は、複数の要素が顧客満足度に与える影響を同時に数値化できる手法であり、「どの施策を優先的に改善すべきか」を客観的に判断するための根拠を提供します。
例えば「価格設定」「スタッフ対応」「店舗環境」「商品ラインナップ」などの評価項目と総合満足度をモデル化することで、最も影響力の大きい要素を特定できます。これにより、漠然とした改善活動ではなくROIの高い施策に絞った効率的な戦略立案が可能となります。特にリソースが限られる中で成果を出す必要がある現場において、重回帰分析は優先順位付けの強力な指標となります。
Pythonで学ぶ実践的なデータ分析ステップ
Pythonはデータ分析の現場で最も広く使われているプログラミング言語の一つです。特に繰り返し処理や大量データの処理・機械学習との連携に強く、Excelでは対応が難しい複雑な分析にも柔軟に対応できます。
ここでは、Pythonで分析を始めるために必要な環境構築から実践的な分析・可視化までの基本ステップを初心者向けに分かりやすく解説します。
Pythonでのデータ分析準備に必要な環境とは
Pythonでデータ分析を行うには、まずは実行環境と基本ライブラリの準備が必要です。初心者におすすめなのが「Anaconda」というオールインワンのパッケージで、Python本体に加え、pandas・NumPy・matplotlib・scikit-learnなど必要な分析ライブラリが一括でインストールされます。
また対話形式でコードを実行できる「Jupyter Notebook」も含まれており、コード・結果・メモを一つの画面にまとめて管理できる点が非常に便利です。GUI感覚で操作できるため、プログラミング未経験者でもスムーズに学習を始められます。
Pythonの実行環境と代表的なライブラリの紹介
Pythonでデータ分析を始めるためには、適切な実行環境を整え、用途に応じたライブラリを理解しておくことが重要です。
以下に初心者でも扱いやすい開発環境や実務で頻繁に使用される主要ライブラリの概要を簡単にご紹介します。
- pandas:表形式データ(CSV、Excelなど)の読み込み・加工・集計
- NumPy:数値計算のための高速配列操作
- matplotlib / seaborn:グラフや可視化のための描画ライブラリ
- scikit-learn:機械学習アルゴリズムやモデル評価ツールが豊富
これらを組み合わせることで、データの整形から予測モデルの構築までを一貫して実施可能です。
Jupyter Notebookの簡単な使い方
Jupyter Notebookは、Pythonコードの記述・実行・結果表示・メモ記入などを1つのインターフェース上で統合的に行える対話型の開発ツールです。セル単位でコードを記述・実行できるため処理の分割や途中経過の確認がしやすく分析の試行錯誤に適しています。
Notebookを起動するには、Anaconda Navigatorまたはターミナル(コマンドプロンプト)からjupyter notebookと入力するだけでブラウザが立ち上がり、プロジェクトフォルダ内での編集が可能になります。セルはコード用とMarkdown用に切り替え可能で説明文や見出しを挿入しながら分析プロセスをドキュメント化できる点も大きな利点です。
また出力結果やグラフを即座に確認できるため、レポート作成やプレゼンテーション資料の下地としても活用されやすい設計となっており、教育用途から実務まで幅広く利用されています。
基本的なデータの読み込みと前処理
データ分析の成功は分析前の準備にかかっていると言っても過言ではありません。特にデータの読み込みや前処理は分析の土台となる工程であり、ここを丁寧に行うことで後続の作業がスムーズになります。
ここでは、CSVやExcelファイルの読み込み、不要な列の削除、欠損値やカテゴリデータの処理などPythonを用いた前処理の基本ステップを簡単に紹介します。
CSVやExcelの読み込みとデータの整形方法
Pythonではpandasライブラリを使うことでCSVやExcelファイルを簡単に読み込むことができます。例えば以下のようなコードでCSVファイルを読み込むことが可能です。
import pandas as pd
df = pd.read_csv("sales_data.csv")
読み込んだデータは、head()で中身を確認したり、columnsで列名を一覧表示することができます。整形作業としては以下のような処理が一般的です。
- 不要な列の削除:df.drop([‘列名’], axis=1)
- 列名の変更:df.rename(columns={‘old_name’: ‘new_name’})
- 日付形式の変換:pd.to_datetime(df[‘date_column’])
こうしたデータ整形を通じて分析に適したクリーンなデータセットを用意しておくことが後の処理効率に大きな差を生みます。
データ前処理でよく使う代表的な処理
データ分析における前処理は分析の土台を整える重要なステップであり、特に「欠損値」や「カテゴリ変数」の扱いは実務でも頻出する課題のひとつです。前処理を適切に実施できていない場合、どれほど高度な分析手法を用いても結果の精度や信頼性を著しく損なうリスクがあります。そのため前処理は単なる準備作業ではなく、分析全体の品質を左右する中核的な工程と捉えるべきです。
まず欠損値への対応は、データの信頼性を確保するうえで不可欠です。データの一部にNaN(欠損値)が含まれている場合、無処理のまま分析に進むとモデルの学習や予測処理にエラーを引き起こす恐れがあります。一般的な対応としては、欠損を含む行を完全に削除する方法(例:df.dropna())が挙げられますが、データ量が限られている場合や欠損が特定の列に偏っている場合は、平均値や中央値といった代表値で補完する手法(例:df[‘列名’].fillna(df[‘列名’].mean()))が有効です。
またカテゴリ変数の処理も重要なポイントです。多くの機械学習アルゴリズムは、文字列データを直接扱うことができないため、カテゴリ変数を数値に変換する前処理が必要となります。代表的な方法としては「男性:0、女性:1」といった数値への変換(ラベルエンコーディング)、あるいはカテゴリごとに新たな列を作成してフラグ化するワンホットエンコーディング(例:pd.get_dummies(df, columns=[‘city’]))などがあります。後者はモデルに不必要な序列を持ち込まずに情報を保持できる点で、特に線形モデルなどとの相性が良いとされています。
こうした前処理の一つひとつは一見地味に思えるかもしれませんが、モデルの予測精度や説明力を大きく左右する極めて重要な工程です。実務においてはこれらの処理を疎かにすることで誤った結果を導いてしまうケースも少なくなく、前処理の丁寧さこそが分析成果の信頼性を担保する要となります。分析の成功はこの基礎的なプロセスにどれだけ真摯に向き合えるかにかかっていると言っても過言ではありません。
scikit-learnを使った回帰・分類モデルの構築
分析対象の傾向や結果を予測するためには、回帰モデルや分類モデルの構築が不可欠です。Pythonの機械学習ライブラリ「scikit-learn」を使えば、これらのモデルを手軽に構築・評価でき、実務で即活用できる予測精度を実現することが可能です。
ここからはscikit-learnを用いたモデル構築の基本と分析初心者が押さえておくべき評価指標について解説します。
データ分析におけるモデルとは
「モデル」とは、現実世界の現象やパターンを数式やアルゴリズムで再現する仕組みを指します。データ分析においては過去のデータを学習し、未知のデータに対して予測や分類を行うための枠組みとして用いられます。
モデルには大きく分けて「回帰モデル(数値予測)」と「分類モデル(カテゴリー分類)」の2種類があり、目的に応じて使い分けます。例えば、売上を予測するには回帰モデル、顧客が離反するかどうかを判断するには分類モデルを用います。適切なモデルを選び正しく評価することで、データから実践的な意思決定につながる示唆を得ることが可能になります。
回帰分析・分類モデルを簡単に試すためのコード構成
scikit-learnでは、わずか数行のコードで回帰・分類モデルを構築し、予測や評価を行うことができます。以下は分類モデルの基本的な流れです(ロジスティック回帰の例)。
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# データの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデルの定義と学習
model = LogisticRegression()
model.fit(X_train, y_train)
# 予測と評価
y_pred = model.predict(X_test)
print("正解率:", accuracy_score(y_test, y_pred))
分類だけでなく線形回帰(LinearRegression)や決定木(DecisionTreeClassifier)なども同様のフローで構築可能です。モデルの構造や目的によって、アルゴリズムを柔軟に切り替えられるのがscikit-learnの強みです。
モデルの評価指標の見方だけは押さえておく
予測モデルを活用して価値ある示唆を得るためには、モデルの性能を適切に評価することが不可欠です。その際に重要となるのが分析の目的やデータの性質に応じた評価指標を正しく選択・理解することです。単に「予測が当たったかどうか」だけに着目するのではなく、予測の精度と実用性のバランスを見極める視点が求められます。
まず回帰モデル(数値予測を行うモデル)の場合に代表的な評価指標を紹介します。
■RMSE(Root Mean Squared Error/平均二乗誤差の平方根):予測値と実測値の差を二乗して平均を取り、それを平方根にした値です。大きな誤差に対して敏感に反応するため、予測精度の安定性を測る上で有効です。値が小さいほどモデルの予測精度が高いとされます。
■MAE(Mean Absolute Error/平均絶対誤差):予測と実測の差の絶対値を平均したもので、外れ値の影響を受けにくいのが特徴です。現実的なズレの大きさを直感的に捉えやすい指標です。
■R²(決定係数):目的変数のばらつきをモデルがどれだけ説明できているかを示す指標で、値は0〜1の間を取ります。1に近いほど説明力が高く、モデルの精度が優れていることを示します。
次に分類モデル(二値・多値分類を行うモデル)の指標を紹介します。
■Accuracy(正解率):全体の中で正しく予測できた割合を示します。データが均衡している場合には有効ですが、クラスに偏りがあるケースでは誤解を招く可能性があるため注意が必要です。
■Precision(適合率)/Recall(再現率)/F1-score:これらは特に不均衡なデータを扱う場面で重要となる指標です。例えば予測対象が非常に少ないケース(例:不正検知や離脱予測)では、単純な正解率ではなくどれだけ適切に重要なクラスを見抜けたかが評価の焦点となります。F1-scoreはPrecisionとRecallの調和平均であり、双方のバランスを考慮した指標です。
■混同行列(Confusion Matrix):実際の値と予測値を行列形式で可視化し、どのクラスをどれだけ正しく、あるいは誤って分類したかを詳細に把握できるため、モデルの挙動を深く理解するのに役立ちます。
これらの評価指標を正しく理解し、目的やデータの特性に応じて使い分けることで分析結果を単なる「当たり外れ」で終わらせず、ビジネスの意思決定に資する実践的な予測モデルを構築することが可能になります。モデル精度の高さだけでなく「どう評価し、どう活用するか」を意識することがデータ分析の成果を最大化するための鍵となります。
データ分析のよくある失敗と解決策

データ分析は適切に進めることで高い成果を生み出せる一方でやり方を誤ると期待した効果が得られない、あるいは誤った意思決定につながるリスクもあります。特に分析初心者や実務での分析未経験者が陥りやすい典型的な失敗にはパターンがあります。
ここでは、よくある3つの失敗事例とその背景、そして具体的な解決策について紹介します。
目的が曖昧なまま分析を始めてしまう
「とりあえずデータがあるから分析してみよう」と目的を明確にせずに始めると途中で方向性を見失ったり結果の解釈に迷うことがよくあります。分析の目的は「売上を伸ばしたい」「離脱率を下げたい」など、ビジネス上の問いを明文化することから始める必要があります。
解決策としては分析前に「仮説・目的・対象・手法・成果物」を1枚のシートで整理し、関係者と共有する「分析設計フェーズ」を設けることが重要です。
手法に詳しくなりすぎて本質を見失う
分析スキルが向上するにつれ、「この手法を使ってみたい」「難易度の高いモデルを試してみたい」といった手段の目的化に陥るケースがあります。ですが実務で求められるのは「正確さ」よりも「活用しやすさ」と「説明のしやすさ」であることが多いです。
分析はあくまで課題解決のための手段であることを忘れず、常に「この分析がどのようなアクションにつながるか」を意識する視点を持ちましょう。
Excel/Pythonの操作ミスによる誤分析
ExcelのオートフィルミスやPythonでのデータ前処理ミス(例:インデックスのずれ、欠損処理の漏れ)など技術的な操作ミスによって分析結果に誤りが生じるケースも少なくありません。特に繰り返し作業や複数のファイルをまたぐ場合、ヒューマンエラーのリスクが高まります。
このような誤分析を防ぐためには処理ごとのログ保存やスクリプトの再現性確保、セルフレビュー体制の整備が効果的です。またコードレビューや二重チェックを仕組みにすることも有効です。
実務に活かす分析フローの全体像と進め方
データ分析を単なる一時的な作業ではなくビジネス成果に直結する継続的な活動として位置づけるには、適切なフローと体制を整えることが不可欠です。分析設計からデータ整備、施策への落とし込みまで体系だったプロセスを踏むことで組織全体に「活きた分析」を根付かせることができます。
ここでは、分析プロジェクトを円滑に進めるための実践的な進行手順と社内体制の構築ポイントを紹介します。
データ分析プロジェクトの成功に導く実践的アプローチ
データ分析は、単に数値や傾向を明らかにすることを目的とするのではなくその結果を現場の意思決定に活かし、具体的なビジネス成果につなげることが真の目的です。にもかかわらず、分析が「報告書の作成」で終わり、現場で実行に移されないまま形骸化してしまうケースは少なくありません。
成功するデータ分析プロジェクトに共通しているのは「分析結果を現場のアクションへ結びつける仕組み」を持っていることです。つまり目的と手段を明確にし、関係者を巻き込みながら継続的に改善を重ねていく実践的な運用体制こそがプロジェクトの成否を分ける鍵となります。
ステークホルダーとのコミュニケーション設計
分析プロジェクトの初期段階では関係者との認識合わせが非常に重要です。ステークホルダーによって「データ分析に求めるもの」は異なるため、目的や期待値を明文化しプロジェクトの方向性を初期段階で共有することが欠かせません。目指す成果や分析に求めるレベル感を早期に共有しておくことで、分析途中での軌道修正や成果物に対する誤解を防ぐことができます。
例えば定例会議やレビュータイミングを明確に設定し進捗状況や一次成果を都度共有することで、分析チームと業務部門の間に信頼関係を築くことができます。
さらに定例の報告や中間レビューを通じて進捗や途中成果を可視化・共有することにより、現場との信頼関係が強化され分析結果の納得性も高まります。こうした丁寧なコミュニケーションの積み重ねが、分析の成果を実行フェーズへと確実につなげる土台になります。
アジャイル手法を取り入れた分析プロセスの進め方
今日のビジネス環境は常に変化しており、データ分析も一度きりの大規模分析では対応しきれません。そのため小さく始めて素早く検証し、改善を繰り返すアジャイル的な進め方が有効です。
例えば小規模なデータセットで仮説を検証し、その結果をすぐに現場へフィードバックすることで、得られた知見を次の施策へつなげます。このようなサイクルを短期間で回すことで、現場との連携を保ちながら柔軟に施策の方向性を調整できる分析体制が構築されます。
効果的なドキュメント管理とナレッジ共有の方法
データ分析の成果を一過性のレポートで終わらせず組織全体の資産として活用していくには、ナレッジの体系的な蓄積と共有が不可欠です。特定の担当者に依存した状態では、分析の再現性や品質の維持が困難になります。
そのために有効なのがデータ辞書や変数定義書の整備、分析レポートのテンプレート化、ナレッジ管理ツール(例:Notion)への集約です。さらにSlackなどのコミュニケーションツールを活用して情報を共有・拡散する仕組みを整えることでナレッジの属人化を防ぎ、チーム全体の分析力を底上げすることができます。
データ収集・加工における品質保証と効率化テクニック
データ分析の成否を大きく左右するのが初期段階である「データ収集」と「データ加工」の工程です。どれほど高度な分析手法を用いたとしても基盤となるデータの品質が担保されていなければ、分析結果に信頼性を持たせることはできません。これらの作業は定期的かつ繰り返し発生するため、業務効率の観点からも標準化や自動化が求められます。
また属人化したデータ処理や更新ミス、異なる部門間でのデータ不整合などが分析プロジェクトの遅延や精度低下の原因となることがあります。したがって、分析に入る前段階で信頼性の高いデータ基盤を整えることが、プロジェクトの成功を支える前提条件となります。
ここでは、実務で押さえておくべきデータ収集・加工フェーズの品質確保と自動化のための基本施策をご紹介します。
データガバナンスの基本と実践
信頼性の高いデータ分析を実現するためには、まずデータガバナンスの仕組みを構築することが欠かせません。データガバナンスとはデータの収集や管理、活用に関するルール、責任範囲を明確にし、全社的に統制を図る枠組みのことです。
特に部門ごとにデータの取り扱いが異なる企業や複数のシステムが混在している環境では、整合性の確保や更新頻度の違いが分析精度に影響を与える可能性があります。そのため実務においては、データの所有者やアクセス権限を明確にし、変数の意味や単位、更新頻度を記載したデータ定義書を整備しておくことが重要です。
さらに定期的に欠損率や重複率といった品質指標をチェックする体制を設けることで、データの信頼性と再利用性が向上します。これにより部門間のデータ共有がスムーズになり、誤った前提に基づく分析や意思決定を未然に防ぐことができます。
ETLプロセスの自動化による効率向上
分析に適したデータを準備するためには、複数のデータソースから必要な情報を抽出し、整形したうえで一元的に格納する「ETL(Extract・Transform・Load)」のプロセスが不可欠です。従来この作業は手動で行われることも多く、ミスの発生や作業の属人化による業務停滞が課題となってきました。
そこで注目されているのがETLプロセスの自動化です。Pythonスクリプトを定期実行するスケジューラー(cronやAirflowなど)を用いた運用、またはTalendやDataSpiderといったクラウドETLツールの活用により定型的なデータ処理を効率的かつ安定して行うことが可能になります。
さらに処理の中にログ出力やエラーハンドリング機能を組み込むことで、トラブル発生時にも原因の特定と対応が迅速に行えるようになります。これにより、日常的な業務負荷の軽減だけでなく分析のスピードアップと品質向上を同時に実現することができます。
オープンデータや外部データソースの効果的な活用法
社内のデータだけでは把握しきれない背景情報やより広い視点からの洞察を得るためにオープンデータや外部データソースを活用する取り組みが増えています。例えば天候や気温のデータは店舗の来店傾向や売上に影響を与える要因となり、人口統計や経済指標はエリア分析や需要予測の精度向上に貢献します。
こうした外部データを分析に取り入れることで視野を広げ、より実態に即した意思決定が可能になります。ただし、その活用にあたっては注意点もあります。まずデータ提供元の信頼性を確認しましょう。公的機関や業界団体など客観性と継続性が担保されたソースを選ぶことが基本です。
さらに対象地域や更新頻度が自社のニーズと合致しているかを確認し、自社データと統合する際には日付やIDなどのキー項目に整合性があるかを検証する必要があります。このように外部データを活用することで単なる内部指標にとどまらずに環境変化も加味した戦略的なデータ分析が実現します。
分析結果をビジネス成果に直結させるための実践ポイント
データ分析の本来の目的はグラフや数値を導き出すことではありません。重要なのは、そこで得られた知見をもとに実際の業務改善や意思決定、さらには売上の向上やコスト削減、顧客満足度の向上といった具体的なビジネス成果に結びつけることです。いかに高度で精緻な分析を行ってもそれが現場で活用されなければ、その価値は限定的なものにとどまります。
ここでは、分析結果を現場に定着させ、組織としての行動変容を促すための実務に根差した具体的なアプローチについて解説します。
データストーリーテリングによる意思決定支援
分析結果を関係者に正しく伝え、理解と行動を促すためには、単に数値やグラフを提示するだけでは不十分です。分析結果が示す事実の背景やそこから導かれる行動の意味を「ストーリー」として構成し、相手の納得感と共感を得る形で伝える力が必要です。
例えば、「購入率が低下している」という結果をそのまま提示するのではなく「特定の年代層でリピート率が下がっており、その要因は直近の施策と関連している。したがって次回キャンペーンでは該当セグメントに特化した内容を打ち出すべき」といった形で課題・原因・対応策を論理的につなげたストーリーとして提示すれば、関係者の理解と実行力は格段に高まります。
このように数字を語るだけでなく、その意味を伝わる形で言語化するスキルが分析をビジネスに活かす鍵となります。
KPIの設定とモニタリング体制の構築
分析から得られた知見を業務改善につなげるためには、具体的な指標(KPI)を設定し、その推移を継続的に追う体制を整えることが重要です。例えば「開封率」「来店頻度」「チャーン率」など施策と連動する数値を明確に設定し、可視化された状態で常にチェックできる仕組みを整えることで現場は改善に向けた具体的な行動を起こしやすくなります。
KPI設計においては、まずは業務目標と直接的に連動しているKPIを設定しましょう。その上で数値の変動に対してどのような要因(ドライバー)が影響しているかを明らかにすることで、数値の変化に対する原因を特定しやすくなります。例えば売上に関するKPIに対しては、広告効果、季節要因、競合の動向などが影響を与える可能性があります。
さらに目標値と現在値、その差分を明確に表示できるダッシュボードを設けて関係者全体で進捗状況を共有できる状態を維持することで迅速な意思決定や課題の早期発見が可能となります。
例えばBIツールやダッシュボードを活用すれば、各部門や担当者がリアルタイムでKPIの状況を把握できる環境を構築することができ、自発的な行動を促す文化の醸成にもつながります。
分析結果を現場に浸透させるためのチェンジマネジメント
データ分析の価値を最大化するためには、現場への浸透が不可欠です。しかし実際には、「分析内容が難解で理解できない」「自分たちの業務にどう関係するのかわからない」といった心理的・構造的なハードルによって分析結果が十分に活用されないことも少なくありません。
このような課題に対応するには、チェンジマネジメントの視点を取り入れることが有効です。つまり分析導入の初期段階から現場とのコミュニケーションを密に取り、施策の背景や目的を丁寧に共有することで納得感と当事者意識を育てていく必要があります。
具体的な取り組みとしては各部門向けに個別の導入支援や説明会を実施し、ツールの操作方法や分析の見方を共有することが効果的です。またダッシュボードの構成を簡素化し、誰でも直感的に操作できるテンプレートを用意することで利用のハードルを下げる工夫も重要です。
さらに現場からのフィードバックを定期的に収集し、それを分析の改善に反映させる仕組みを作ることで、現場と分析チームが互いに意見を交換しながら改善を進められる体制を整えられます。こうした仕組みを整えることで分析が一過性の活動にとどまらず、継続的に価値を生み出す組織文化の中核として機能するようになります。
まとめ
ここまで「データ分析 手法」というテーマに基づき、基本的な考え方から代表的な手法、実務での選び方、ツール別の活用方法、そしてビジネス現場で成果を出すための実践的なノウハウまでを解説しました。
データ分析は、一部の専門家に限られた領域ではなく今やすべてのビジネスパーソンが扱うべき共通言語としての役割を担いつつあります。大切なのは手法をただ習得することにとどまらず、目的に応じて適切に活用し、得られた結果を実践的なアクションへとつなげる思考力を養うことです。
まずExcelによるクロス集計や可視化からスタートし、徐々にPythonやscikit-learnによる高度な分析へとスキルを拡張していきましょう。また分析結果を活かすには、組織内での共有やKPI設計、現場への落とし込みといった「運用視点」も欠かせません。
正しい手法と進め方を理解し目的を見失わずに分析を実行できれば、データは確実にビジネスの意思決定を強化する武器になります。
ストラではデータ分析、マーケティングに精通したプロフェッショナルが、データ分析はもちろん、データ分析基盤構築、内製化支援まで一貫してご支援可能です。データ分析についてお困りごとがありましたら、まずはお気軽にご相談ください。
また、ストラのBtoBマーケティング戦略策定支援やBtoBマーケティング伴走支援、データ分析支援について、さらに詳しく知りたい方はこちらのページで紹介しています。
データ分析のお困りごとはプロにご相談ください
- 社内にデータが蓄積されていて分析を始めたいけど、まず何から学べばいいのか分からない
- 解決したい課題からデータ分析の目的を明確にし、それに合致した手法を採用したい
- データ活用の推進プロジェクトを立ち上げたもののプロジェクトが失敗してしまう
執筆者 代表取締役社長 / CEO 杉山元紀
大学卒業後、株式会社TBI JAPANに入社。株式会社Paykeに取締役として出向し訪日旅行者向けモバイルアプリ及び製造小売り向けSaaSプロダクトの立ち上げを行う。
アクセンチュア株式会社では大手メディア・総合人材企業のセールス・マーケティング領域の戦略策定や業務改革、SFA・MAツール等の導入及び活用支援業務に従事。
株式会社Paykeに再入社し約10億円の資金調達を行いビジネスサイドを管掌した後、Strh株式会社を設立し代表取締役に就任。
▼保有資格
Salesforce認定アドミニストレーター
Salesforce認定Marketing Cloudアドミニストレーター
Salesforce認定Marketing Cloud Account Engagementスペシャリスト
Salesforce認定Marketing Cloud Account Engagement コンサルタント
Salesforce認定Sales Cloudコンサルタント
Salesforce認定Data Cloudコンサルタント
この記事をシェアする
