Agentforceのデータライブラリとは?仕組み・設定方法・活用例まで実務目線で徹底解説

この記事をシェアする


この記事でわかること
- Agentforceのデータライブラリとは何か
- Agentforceのデータライブラリの仕組みと回答生成までの流れ
- Agentforceのデータライブラリを導入するメリットと注意点
- Agentforceのデータライブラリの設定方法と作成手順
- Agentforceのデータライブラリの具体的な活用例

執筆者 取締役 / CTO 内山文裕
Agentforceの導入や活用のお困りごとはプロにご相談ください
- Agentforceのデータライブラリを導入したいが、どのデータを参照させるべきか整理できていない
- 社内マニュアルや規程をデータライブラリに取り込んだものの、回答精度が安定せず原因が分からない
- データ更新や権限設定など、データライブラリの運用ルールをどのように設計すべきか悩んでいる
Agentforceをこれから業務に取り入れようと考えたとき、「本当に正しい内容を答えてくれるのか」「社内の決まりと違うことを案内してしまわないか」と不安に感じる方も多いのではないでしょうか。まだ広く使われている段階ではないからこそ、安心して使えるのかをきちんと理解してから判断したいと思うのは自然なことです。
Agentforceのデータライブラリは社内のマニュアルや規程、よくある質問などを回答の根拠として参照させるための仕組みです。あらかじめ自社の情報をもとに答えるよう設定しておくことで、思いつきのような回答ではなく、自社ルールに沿った案内をしやすくなります。
本記事ではこれから導入を検討する方に向けて、データライブラリとは何か、導入するメリットと注意点、設定するときや実際に使うときの流れ、具体的な活用例までを徹底的に解説します。自社で使うべきかどうかを判断できるよう、順を追って整理していきます。
また、Agentforceについて振り返りたい方はこちらの記事を参考にしてください。
【最新】SalesforceのAgentforceとは?機能や価格などを徹底解説
目次
Agentforceのデータライブラリとは
Agentforceのデータライブラリとは社内や業務で使っている情報を根拠として参照させ、回答の信頼性を高めるための仕組みです。まだ導入していない企業にとっては、「本当に正しい内容を答えてくれるのか」という不安を解消する上で押さえておきたい機能といえるでしょう。
例えば顧客対応を行う部門では、返金条件や契約内容を正確に案内する必要があります。情報システム部門では、社内マニュアルや規程に沿った案内が求められます。営業支援の場面でも、商品仕様や料金体系を誤りなく説明することが重要です。データライブラリを活用することで、こうした業務において自社の情報をもとに回答しやすくなります。
Agentforceのデータライブラリはデータソースを設定できる機能
データライブラリは、Agentforceのエージェントなどの機能を信頼できるデータソースに接続することで回答精度を高める仕組みです。あらかじめ参照させたい情報を設定しておくことで、その情報をもとに回答を生成できるようになります。
そのため社内ナレッジやData Cloudに蓄積された情報など自社が保有しているデータを根拠として回答を作ることが可能になります。一般的な知識だけに頼るのではなく、自社の実情に合った案内をしやすくなるのが大きな特長です。
Agentforceのデータライブラリを導入するメリット、デメリット
Agentforceのデータライブラリの導入を検討するうえで重要なのは「できること」だけでなく、「導入すると何が変わるのか」を正しく理解することです。特に業務工数は減るのか、回答の精度はどの程度安定するのか、どのような運用体制が必要になるのかといった点は事前に整理しておくべきポイントになります。
メリットだけを見て導入を決めてしまうと、想定外の手間や管理負荷に戸惑う可能性があります。一方で注意点ばかりを気にしていると、本来得られる効果を見逃してしまうこともあります。だからこそメリットとデメリットの両方を具体的な業務目線で理解することが大切です。
本章では導入によって現場にどのような変化が生まれるのかを整理しながら、メリットとデメリットを順番に解説します。判断に必要な観点を明確にし、自社にとって現実的な選択ができるようにしていきます。
Agentforceのデータライブラリを導入するメリット

導入によって何が良くなるのか、その背景にある理由は何か、そして実際にどのような場面で効果を発揮するのか。この3点をセットで理解することが、判断を誤らないためのポイントです。効果だけを見るのではなく、「なぜその効果が生まれるのか」まで押さえることで、自社に当てはめたときの現実的なイメージが持てるようになります。
根拠にもとづく信頼性の高い回答を作りやすい
データライブラリを使う一番のメリットは、「それらしく聞こえるだけの回答」を減らせることです。あらかじめ社内のマニュアルや規程、商品情報などを参照するように設定しておくため、回答にきちんとした裏付けを持たせやすくなります。
例えばよくある質問への回答や社内規程の案内など、間違いが許されない業務では特に効果があります。担当者の経験や記憶に頼るのではなく実際の資料をもとに説明できるため、回答のばらつきを抑えやすくなります。
ナレッジ整備・更新の運用に乗せやすい
データライブラリを前提にすると、情報管理の運用が行いやすくなります。なぜなら「どの資料を参照させるのか」を明確にする必要があるため、最新版の管理や古い資料の整理を自然と行うようになるからです。
例えば「マニュアルを改訂したら必ず差し替える」「使わなくなった規程は参照対象から外す」といった運用ルールを決めておけば、常に最新情報をもとに回答できる状態を保ちやすくなります。情報の管理体制が整うほど回答の精度も安定していきます。
ユースケース展開を想定した設計にしやすい
データライブラリは対象業務をしぼって始められる点も利点です。業務ごとに参照する情報を分けて設定できるため、いきなり全社展開を目指す必要はありません。
例えばまずは顧客対応の一次回答だけに限定して導入し、効果を確認したうえで社内ヘルプデスク対応へ広げるといった進め方ができます。小さく始めて段階的に展開できるため、導入の負担やリスクを抑えながら活用範囲を拡大していくことが可能です。
Agentforceのデータライブラリを導入するデメリット

データライブラリは便利な仕組みですが、導入すれば自動的にうまくいくわけではありません。特にまだ使っていない段階では「思ったより手間がかかるのではないか」「管理が複雑になるのではないか」と不安を感じやすい部分です。
ここではデメリットを現場で起きやすい課題とあわせて、実務上の回避策や運用のコツも簡潔に整理します。
取り込み・反映に時間差が出る
データライブラリでは資料を更新してもその内容がすぐに回答へ反映されない場合があります。そのため更新した直後に確認すると、まだ古い内容で答えてしまうことがあります。
この特性を理解せずに運用すると、「修正したのに直っていない」という不信感につながりかねません。実務では反映までに一定の時間がかかることを前提に、更新のタイミングをあらかじめ決めておくことが重要です。
また更新後には必ずテスト用の質問を行い、想定どおりの回答になっているかを確認する流れを組み込んでおくと安心です。
文書品質次第で検索・回答精度が揺れる
データライブラリは登録された文書をもとに回答を作ります。そのため元となる文書の書き方や整理状況によって、回答の精度が大きく左右されます。
例えば同じ意味の言葉が資料ごとに異なる表現で書かれていたり、見出しが整理されておらず長文の中に重要な情報が埋もれていたりすると、必要な情報をうまく見つけられないことがあります。また一つの文書に複数の話題が混在している場合も、回答があいまいになりやすくなります。
そのため用語をできるだけ統一することや見出し構造を整えること、一つの文書では一つのテーマを扱うことなど最低限の整備ルールを決めておくことが重要です。導入前に既存資料の状態を確認し、どこまでそのまま使えるのかを見極めておくと導入後の混乱を防ぎやすくなります。
権限設計・ガバナンス設計が必要になる
データライブラリでは誰がどの情報を参照できるかによって、生成される回答内容が変わります。つまり権限の設定次第で答えも変わるということです。
もし権限設計が不十分なまま導入すると、本来見せるべきではない情報が回答に含まれたり、逆に必要な情報が参照できず不完全な回答になったりする恐れがあります。
そのため機密情報の区分を明確にし、部門ごとの公開範囲を整理し、利用状況を確認できる仕組みを用意しておく必要があります。
これは単なる設定作業ではなく、情報管理の方針そのものに関わるテーマです。後ほど解説する「同じ質問でも答えが変わる原因」にもつながるため、導入時には必ず検討しておくべきポイントです。
Agentforceのデータライブラリの設定時に行われる処理
データライブラリを設定するとき、多くの方が「画面でボタンを押すと何が起きているのか分からない」という不安を感じます。導入前の段階では仕組みが見えないこと自体が判断の妨げになります。
そこで重要なのは「設定画面で何をすると、裏側で何が行われるのか」をセットで理解することです。ブラックボックスのままにせず、内部の流れを大まかにつかんでおくことで、導入後のトラブルにも落ち着いて対応できるようになります。
本章では設定時に内部でどのような処理が順番に実行されているのかを整理し、画面操作と裏側の動きを対応させながら解説します。
Agentforceのデータライブラリの仕組み
データライブラリを正しく理解するには、内部でどのような考え方や処理が使われているのかを押さえておくことが大切です。用語だけを見ると難しく感じますが、それぞれの役割を順番に理解すれば、全体の流れはシンプルです。
この仕組みを知っておくと「なぜ元データの整備が重要なのか」「なぜ更新してもすぐに反映されないことがあるのか」といった疑問も自然とつながって理解できるようになります。
ここではデータライブラリを支えている基本的な考え方と主要な用語について解説します。
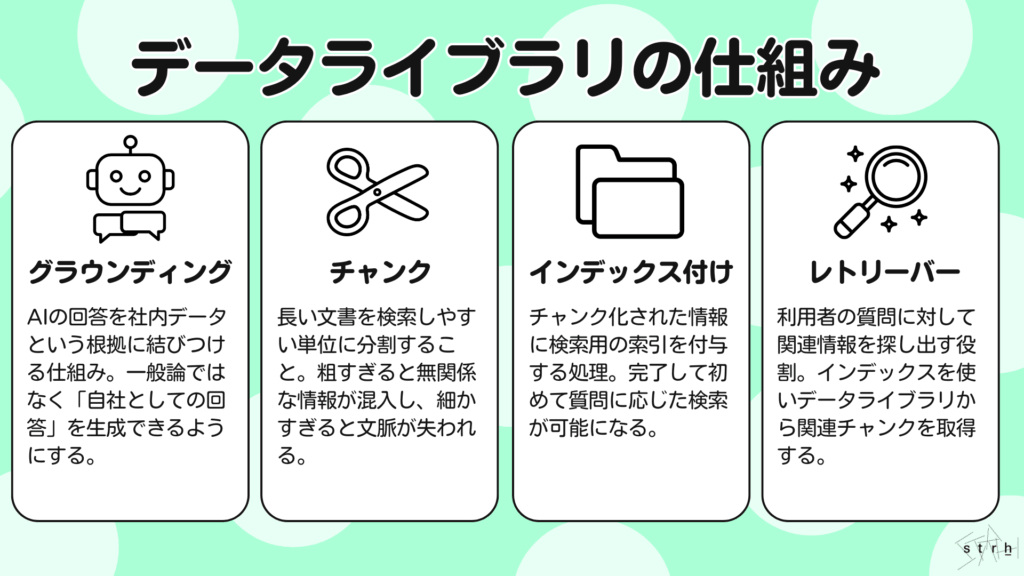
グラウンディングとは
グラウンディングとはAIの回答を社内データという根拠に結びつける仕組み、または考え方のことです。
通常、AIは学習済みの一般知識をもとに文章を作ります。しかし業務で求められるのは、一般論ではなく「自社としてどうなのか」という回答です。そこで社内規程や商品仕様、契約条件などの情報を参照させ、その範囲内で答えさせるのがグラウンディングです。
例えると、自由回答式の試験ではなく「持ち込み可の資料を使って答える試験」に近い状態をつくるイメージです。根拠が明確になることで回答の理由を説明しやすくなり、特に顧客対応や監査対応の場面で安心して利用できるようになります。
チャンクとは
チャンクとは長い文書を検索しやすい単位に分割することです。例えば50ページの業務マニュアルをそのまま一つのかたまりとして扱うのではなく、「第1章 申請手順」「第2章 承認フロー」といった単位に分けて管理します。さらに細かく項目単位で分割することもあります。
なぜ分割が必要かというと、質問に対して関係のある部分だけを正確に見つけるためです。分割が粗すぎると関係のない情報まで含まれてしまい、逆に細かすぎると文脈が失われることがあります。つまり、チャンクの切り方は回答の当たりやすさや分かりやすさに影響する重要な要素です。
インデックス付けとは
インデックス付けとは取り込んだ情報を検索可能な状態にするための索引作成の処理です。
図書館に例えると、本を棚に並べるだけでなくタイトルや著者名、分類番号を登録して検索できるようにする作業にあたります。データライブラリでもチャンク化された情報に対して検索用の情報を付与し、「どんな質問と関連があるか」を判断できる状態にします。
この処理が完了してはじめて、質問に応じた検索が可能になります。資料を追加・更新してもインデックス付けが終わるまでは十分に検索できないため、反映までに時間差が生まれることがあります。
レトリーバーとは
レトリーバーとは利用者の質問に対して、関連する情報を探し出して持ってくる役割を担う仕組みです。利用者が質問を入力すると、まずレトリーバーがインデックスを使ってデータライブラリの中から関連性の高いチャンクを探します。その後、見つけた情報を材料としてAIが回答文を作成します。
つまり流れとしては「質問する → 情報を探す → 見つけた情報をもとに答える」という順番になります。このような、まず探してから答える構造こそがデータライブラリによって回答の信頼性を高めるポイントです。
この仕組みを理解しておくと、なぜ元データの質や権限設定が回答に影響するのかについても、より具体的にイメージできるようになります。
Agentforceのデータライブラリ設定時に行われるフロー
データライブラリを設定画面で作成すると、裏側では決まった順番で処理が進みます。参考図にある流れに沿って、「どのタイミングで何が起きているのか」を順番に整理します。
ポイントは、いきなり回答に使える状態になるのではなく「準備 → 整理 → 検索可能化 → 利用可能化」という段階を踏んでいるということです。
ここでは設定操作にあわせて内部でどのような処理が実行されているのかを工程ごとに解説します。
①データストリーム、続いてデータレイクとデータモデルオブジェクトが作成される
最初に行われるのは、データを取り込むための入口と保存する場所の準備です。
データストリームは外部や内部のデータを取り込むための通り道のような役割を持ちます。その後、取り込んだデータを保管する場所としてデータレイクが用意され、さらにそのデータを扱いやすい形に整理するためのデータモデルオブジェクトが作成されます。
イメージとしては「データを流し込む管をつくり、保管庫を用意し、整理用の箱を準備する」段階です。まだ検索や回答には使われず、あくまで土台づくりの工程になります。
②オブジェクトが対応付けられ、データのチャンク化が開始
次に扱うデータとその形式の対応関係を整理し、データライブラリで活用する情報の範囲や内容をここで明確にします。
対応付けが完了すると、データはチャンク化されます。つまり長い文書や大量のデータが、検索しやすい小さな単位に分割されていきます。
この段階で元の文書の書き方や構造が大きく影響します。見出しが整理されている文書は分割もしやすく、検索精度も安定しやすくなります。逆に情報が整理されていない文書は、ここで扱いづらさが表面化します。
③チャンク化が完了し、検索インデックスの準備ができたら、レトリーバーが作成される
チャンク化が終わると、それらの情報に対して検索インデックスが作られます。これは質問に応じて関連情報を探せるようにするための土台です。この検索の仕組みが整ったあとに、レトリーバーが作成されます。レトリーバーは実際に質問を受けたときに情報を探しに行く役割を担います。
つまり「情報を分ける → 探せるようにする → 探しに行く役を用意する」という順番です。このレトリーバーが用意されたタイミングで、はじめてデータライブラリが実際の回答生成に使える状態になります。
この流れを理解しておくと、どの工程で時間がかかるのか、どの工程が精度に影響するのかが見えやすくなります。
Agentforceのデータライブラリの実行時に行われる処理フロー
データライブラリを設定したあと実際にユーザーが質問すると、内部では決まった順番で処理が進みます。参考図に沿って流れを理解すると「どこで情報を探しているのか」「どの段階で文章が作られているのか」が見えてきます。
重要なのは、いきなり文章を作っているわけではないという点です。まず調べ、材料を集めたうえで文章を作るという順番になっています。
本章ではユーザーの質問がどのような役割分担のもとで処理され、最終的な回答に至るのかを工程ごとに解説します。
ユーザーの質問から回答までの流れ
実行時の処理は、単に「質問に対して答えを返す」という単純な動きではありません。内部では、役割ごとに分担しながら段階的に処理が進みます。中心となるのがプランナー、Knowledge Action、LLMの三つの役割です。それぞれが異なる責任を持ち、連携することで回答が生成されます。
ここではユーザーの質問がどのように解釈され、どの順番で情報が集められ、最終的な文章として返されるのかを、工程ごとに解説します。
①質問をプランナーが受け取り、「何を調べるべきか」を整理する
最初に動くのがプランナーです。プランナーは全体を指揮する司令塔の役割を担います。
ユーザーの質問をそのまま検索にかけるのではなく、まず「この質問の意図は何か」「確認すべき論点は何か」を分解します。例えば「返金は可能ですか」という質問であれば、プランナーは返金条件、対象期間、例外規定など確認すべき要素を整理します。
この段階での解釈がずれると、後続の検索もずれてしまいます。つまり、ここは単なる受付ではなく、回答の方向性を決める重要な工程です。
②Knowledge Actionが、検索インデックスを使ってデータライブラリ内の関連箇所を探す
調査の方向が決まると、Knowledge Actionが実際の検索を行います。役割は必要な情報をデータライブラリの中から見つけ出すことです。
イメージとしては図書館でテーマに合った本を探し、その中から該当ページを開く作業に近いものです。あらかじめ作られている検索インデックスを使い、質問内容と関連性の高いチャンクを抽出します。
重要なのは推測で文章を作らないという点です。必ず「探す」という工程を経てから回答が作られます。この構造が、グラウンディングの実行部分にあたります。
③見つかった情報をKnowledge Actionがプランナーに返し、回答に使う材料としてまとめる
検索によって見つかった情報はそのまま文章になるわけではありません。いったんプランナーに渡され、回答に使う材料として整理されます。ここはいわば材料集めの工程です。必要な情報が十分に集まっているか、重複や矛盾がないかを確認しながら、回答の土台を整えます。
この段階での材料の質がそのまま回答の質に直結します。元データが整理されていれば、的確で一貫した材料が集まりやすくなります。一方で情報が不足していたり曖昧だったりすると、回答も抽象的になりやすくなります。データライブラリの整備状況がここで明確に影響します。
④LLMが文章を作り、プランナーが読みやすい形に整えて返す
材料がそろうと、LLMがその内容をもとに文章を作成します。LLMの役割は集められた情報を自然で分かりやすい文章にまとめることです。
ただし、ここでも完全に任せきりではありません。プランナーが生成された文章の読みやすさや構成を整え、必要に応じて文章が補足されます。場合によっては要点をまとめたり、重要部分を強調したりすることもあります。
このように実行時の流れは「質問を理解する → 調査方針を決める → 情報を探す → 材料を整理する → 文章にまとめる」という段階を踏んで進みます。この構造を理解しておくことで、「どの工程が弱いと回答がぶれるのか」「どこを改善すれば品質が安定するのか」が見えやすくなります。
ユーザーからの同じ質問でも答えがブレる原因
実際に運用を始めると「同じような質問なのに、回答の内容が少し違う」と感じる場面が出てくることがあります。これは不具合とは限らず、仕組み上起こり得る現象です。
原因は大きく分けて二つあります。一つはデータそのものの状態、もう一つは権限や処理上の制約といった条件面です。この二つを理解しておくことで、後から慌てずに対策を取れるようになります。
ここではその原因を、データ側の要因と制約側の要因に分けて解説します。
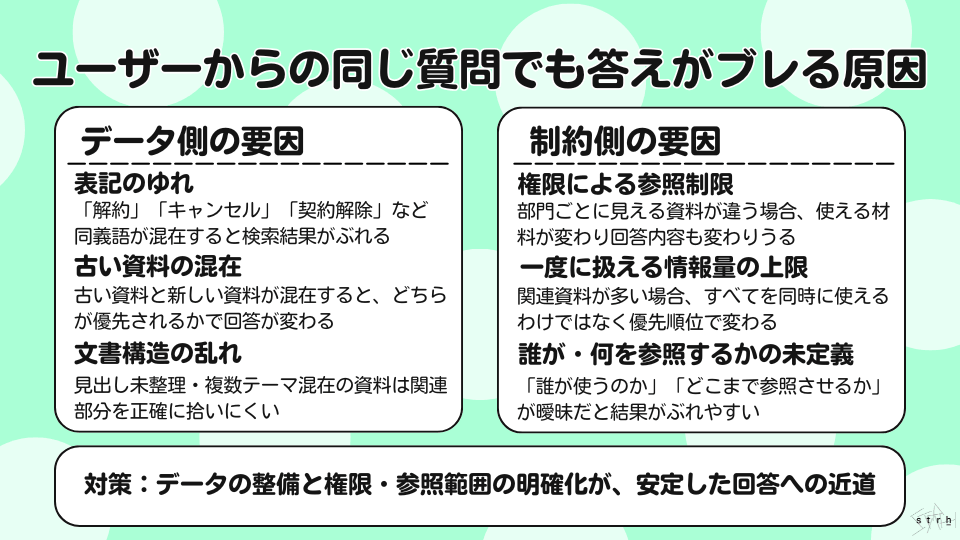
検索の当たりやすさは「元データの整備」で決まる
まず大きく影響するのが、データライブラリに登録している元データの状態です。例えば、同じ意味なのに資料ごとに「解約」「キャンセル」「契約解除」と異なる表現が使われている場合、検索の結果が揺れることがあります。また古い資料と新しい資料が混在していると、どちらが優先されるかによって回答が変わることもあります。
さらに見出し構造が整理されていない文書や複数のテーマが一つの資料に詰め込まれている文書は、関連部分を正確に拾いにくくなります。
つまり検索の精度はシステムだけで決まるのではなく、元データの整備状況に大きく左右されます。用語の統一や最新版の明確化、テーマごとの整理といった基本的な整備が、回答の安定につながります。
参照できる情報量は「権限」と「上限」で決まる
もう一つの要因は参照できる範囲と量の制約です。まず利用者の権限によって見える情報が異なります。ある部門では参照できる資料が別の部門では参照できない設定になっていれば、同じ質問でも使える材料が変わります。その結果、回答内容も変わる可能性があります。
また、一度に扱える情報量には限りがあります。関連する資料が多すぎる場合、すべてを同時に材料として使えるわけではありません。どの情報が優先されるかによって、回答の表現や強調点が変わることがあります。
そのため「誰が使うのか」「どこまでの情報を参照させるのか」を明確にしておくことが重要です。この点は、先ほど触れた権限設計やデータ整備の話ともつながります。
同じ質問でも答えがブレる可能性を理解したうえで、データの整備と運用ルールを整えることが、安定した活用への近道です。
Agentforceのデータライブラリの作成手順
データライブラリの作成は、画面上では数ステップで完了します。しかし、どのタイミングで何を設定しているのかを理解していないと「どこで止まっているのか分からない」という状態になりがちです。
本章では、実際の画面遷移をイメージできるように、操作の流れとあわせて「つまずきやすいポイント」も整理します。
データライブラリの作成に必要な権限・前提機能
データライブラリの作成は、事前準備が不足していると途中で手順が止まります。操作に入る前に、必要な権限と前提機能を確認しておくことが重要です。まず、Agentforceおよびデータライブラリを作成・編集できる管理権限が付与されている必要があります。設定メニューに対象項目が表示されない場合は、権限不足の可能性があります。
次に、参照予定のデータソースが利用可能な状態であることが前提です。例えばData Cloudのデータを使う場合は、対象データが取り込まれ、利用可能な状態になっている必要があります。データが未整備のままでは、ライブラリを作成しても意味を持ちません。
また、いきなり本番環境で作成するのではなく、Sandbox環境で検証することが推奨されます。検索精度や回答内容を事前に確認することで本番での混乱を防げます。
データライブラリの作成ステップ
ここからは、実際にデータライブラリを作成する具体的な手順を解説します。単に操作を並べるのではなく、「何を操作するのか」と「その結果、どの状態になっていれば正しく進んでいるのか」をセットで確認していきます。
この「操作と期待状態のセット」を意識することで、今どの工程にいるのか、どこで止まっているのかを判断しやすくなります。特に初回設定では裏側で処理が走っていることに気づかず不安になるケースが多いため、各ステップで確認すべきポイントを明確にしておくことが重要です。
また作成作業は単なる設定ではなく、「どの業務に、どの情報を根拠として持たせるか」を決める設計作業でもあります。そのため、画面操作と同時に、目的や利用シーンを意識しながら進めることが成功のポイントになります。
ここでは実際の画面遷移をイメージできるように、順番に説明していきます。
① 設定でAgentforceのデータライブラリに移動
操作としては設定画面に入り、Agentforce関連メニューから「データライブラリ」を選択します。
正しく到達できていれば、既存のライブラリ一覧と「新規作成」ボタンが表示されます。この一覧画面が見えていれば、権限と機能は問題ありません。メニュー自体が表示されない場合は、権限設定を確認します。
② ライブラリ名を入力して保存
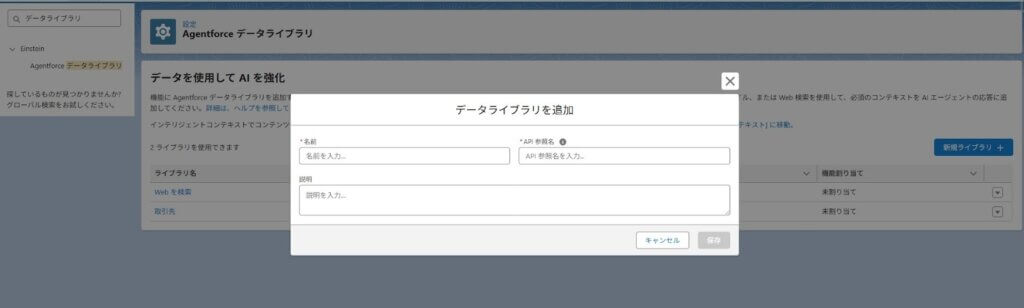
新規作成を選択し、ライブラリ名を入力して保存します。
命名は非常に重要です。例えば「CS一次対応用」「社内ヘルプデスク用」など、用途が分かる名前にしておくと運用時に迷いません。後から複数ライブラリを管理することを想定して命名します。
保存すると、裏側ではデータ処理の準備が始まります。すぐに利用可能になるわけではなく、反映待ちの時間が発生する場合があります。この段階で焦らず、処理状況を確認することが大切です。
③ ライブラリのデータソースの選択
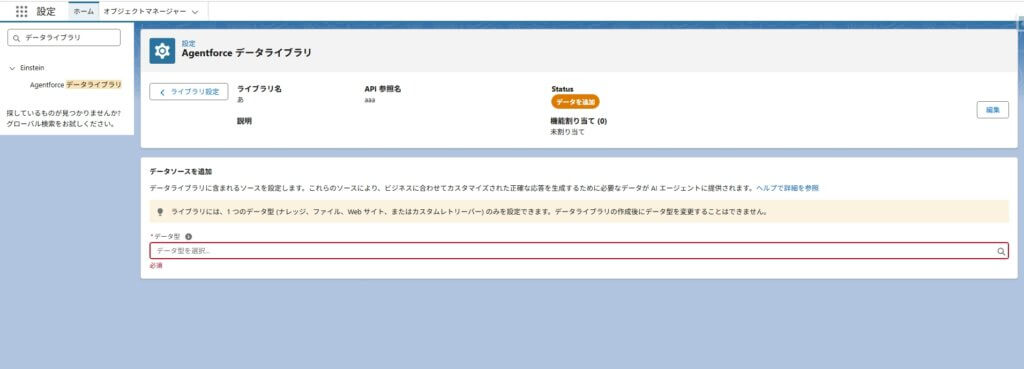
次にどのデータをこのライブラリで参照させるかを選択します。
ここが精度を左右する重要なポイントです。社内規程、マニュアル、FAQ、製品仕様書など、どの情報を正とするのかを明確にします。古い資料や未整理の資料を含めると、回答品質に影響します。
判断基準としては、「この業務で根拠にしたい情報は何か」を軸に選定します。目的に合わないデータを含めると、検索結果が散らばりやすくなります。
④ 機能へのデータライブラリの割り当て
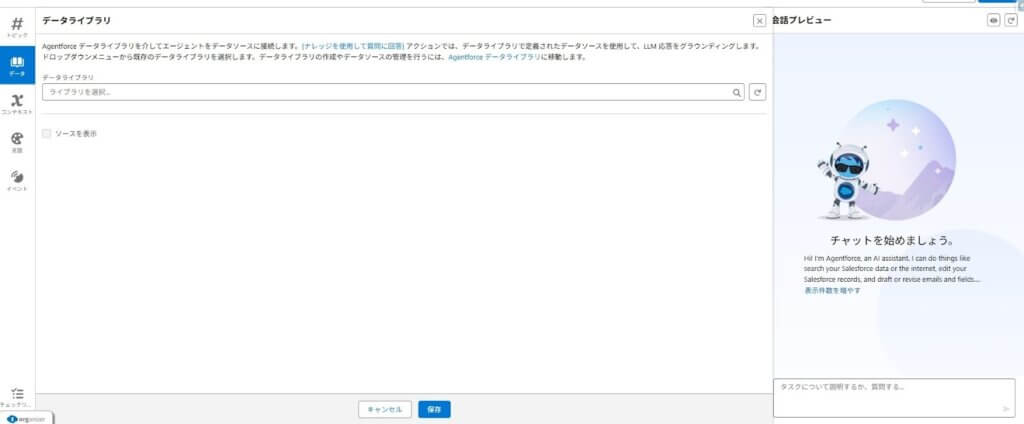
対象のエージェントまたは機能の設定画面を開き、参照先として利用するデータライブラリを選択して保存します。
作成しただけでは、エージェントはまだこのライブラリを参照できません。利用させたいエージェントや機能に対して、参照先としてデータライブラリを割り当てる必要があります。
この設定によって、どのエージェントがどのライブラリを利用するのかが定まり、ライブラリの内容を実際の動作に反映できるようになります。
⑤ Sandboxでのデータライブラリのテスト
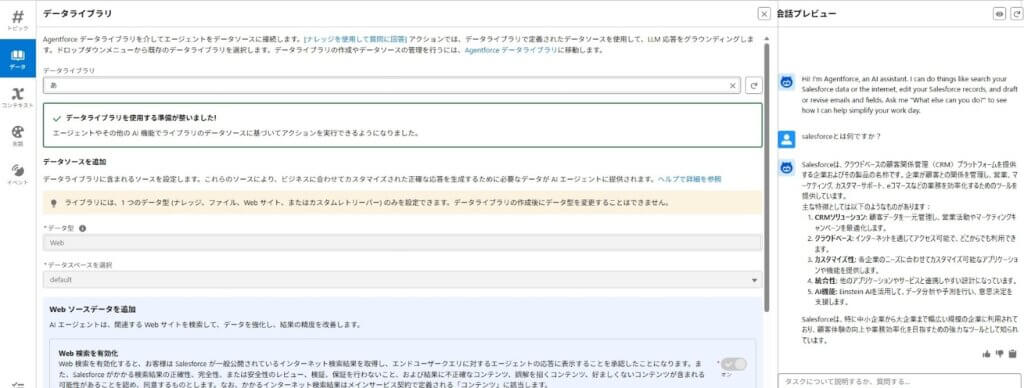
最後に、Sandbox環境でテストを行います。本番前の検証は必須です。
テストでは次の観点を確認します。
・想定している質問で正しい情報がヒットするか
・権限を変えた場合に表示内容が適切に出し分けられるか
・資料を更新した後、正しく反映されるか
これらを確認できれば、基本的な設定は問題ありません。
Agentforceのデータライブラリの活用例
データライブラリは設定そのものが目的ではありません。実際の業務の中で使われて初めて価値が出ます。ここでは導入後のイメージを具体的に持てるように、代表的な三つの業務シーンでどのように活用できるのかを整理します。いずれも「どの業務で」「どんな問い合わせが多く」「データライブラリによって何が変わるのか」という順番で見ていきます。
本章では実際の業務場面を想定しながら、導入後にどのような変化が起きるのかを具体的に解説します。自社に当てはめたときに活用できるかどうかを判断できるよう、現場目線で整理していきます。
カスタマーサポートの一次対応での活用
対象業務は顧客からの問い合わせに対する一次対応です。特にメールやチャットでの初期回答を担うチームで効果を発揮します。
よくある問い合わせとしては、「解約は可能か」「返金条件は何か」「操作手順を教えてほしい」といったFAQや利用手順に関する質問が挙げられます。これらは件数が多く、担当者ごとの回答品質の差が出やすい領域です。
データライブラリを活用すると社内FAQや利用ガイド、規約を根拠として参照しながら回答を作成できるようになります。その結果、返信時間の短縮が期待できるだけでなく、回答内容のばらつきも抑えられます。一次対応で自己解決につながる割合が増えれば、二次対応へのエスカレーション件数の削減にもつながります。
社内ヘルプデスクでの活用
対象業務は情報システム部門や総務部門などが対応する社内問い合わせです。
よくある問い合わせには「アカウントの申請方法を教えてほしい」「パスワードを変更したい」「新しい端末の設定手順を知りたい」「利用中のツールの操作方法を確認したい」といった内容があります。このような定型的な質問は繰り返し発生する一方で、手順が更新されやすいという特徴もあります。
データライブラリを使えば、最新の申請マニュアルや利用ガイドを参照しながら回答を提示できます。これにより、担当者が毎回説明を書く手間を減らせるだけでなく、古い手順を案内してしまうリスクも抑えられます。結果として、対応工数の削減と情報の標準化の両立が期待できます。
営業・CSのナレッジ参照での活用
対象業務は営業やカスタマーサクセスが商談中や顧客対応中に情報を確認する場面です。
よくあるシーンとしては「このプランの料金条件はどうなっているか」「特定の機能はどの契約で使えるのか」「更新時の条件は何か」「運用ルール上どこまで対応可能か」といった確認があります。これらは即答が求められる一方で、規約や社内ルールに基づいた正確な回答が必要です。
データライブラリを活用すれば、規約や料金表、運用ルールなどをその場で参照し、根拠を持って説明できます。資料を探す手間を減らせるため、必要な情報をその場で確認しながら商談や打ち合わせを進めやすくなります。
まとめ
Agentforceのデータライブラリは、社内や業務データを回答の根拠として活用し、信頼性の高い応答を実現するための仕組みです。単に便利な機能というだけでなく、「どの情報をもとに答えるのか」を明確にできる点が大きな価値です。
一方で、導入すれば自動的にうまくいくわけではありません。元データの整備状況や権限設計、更新運用の設計によって、回答品質や安定性は大きく左右されます。設定時にどのような処理が行われているのか、実行時にどの順番で回答が作られているのかを理解しておくことで、ブラックボックスへの不安も軽減できます。
これから導入を検討する場合は、まず対象業務を明確にし、小さな範囲で検証することが現実的です。データ整備と運用ルールを整えながら段階的に広げていくことで、回答品質の向上と業務効率化の両立が見えてきます。Agentforceのデータライブラリは正しく設計し運用することで、回答に根拠を持たせる土台となる仕組みだからです。
またAgentforceを始め、自社でSalesforce製品を上手く使っていけるか、全体最適化についてご相談をしたいというご担当者様は、ぜひ一度弊社ストラへお問い合わせくださいませ。
ストラでは、各社様が実現したい業務フローや体制をヒアリングした上で、Salesforce製品を活用していくその先のゴールまでを踏まえ、適切なSalesforceの環境設定や運用を支援いたします。
ストラのSalesforce導入支援や定着化支援、開発支援についてさらに詳しく知りたい方はこちらのページで紹介しています。
Agentforceの導入や活用のお困りごとはプロにご相談ください
- Agentforceのデータライブラリを導入したいが、どのデータを参照させるべきか整理できていない
- 社内マニュアルや規程をデータライブラリに取り込んだものの、回答精度が安定せず原因が分からない
- データ更新や権限設定など、データライブラリの運用ルールをどのように設計すべきか悩んでいる

執筆者 取締役 / CTO 内山文裕
青山学院大学卒業後、株式会社ユニバーサルコムピューターシステムに入社。
大手商社のB2B向けECサイトの構築にて会員登録、見積・注文機能、帳票出力などECにおける主要機能のフロント画面・バックエンドの開発に従事。 その後アクセンチュア株式会社に入社。デジタルコンサルタントとしてWebフロントエンド・モバイルアプリの開発やアーキ構築を主に、アパレル・メディア・小売など業界横断的にシステム開発を支援。また、ビッグデータを活用したマーケティング施策の策定やMAツールの導入・運用支援にも従事。
2022年2月にStrh株式会社の取締役CTOに就任。デジタルプロダクト開発の支援やMAツール導入・運用支援を行っている。
▼保有資格
Salesforce認定アドミニストレーター
Salesforce認定Java Scriptデベロッパー
Salesforce 認定Data Cloudコンサルタント
この記事をシェアする
